This HTML file was generated by portable-php.
In the world of AI and machine learning, setting up models on local machines can often be a daunting task. Especially when you're dealing with state-of-the-art models like GPT-3 or its variants. I've personally grappled with the frustrating process of setting up Llama2 on my machine. After numerous attempts, I stumbled upon a gem: GPT4All.
What is GPT4All?
GPT4All is an open-source platform that offers a seamless way to run GPT-like models directly on your machine. The beauty of GPT4All lies in its simplicity. Not only does it provide an easy-to-use interface, but it also offers downloadable models, making the entire process straightforward.
Having tried multiple methods to set up GPT-like models on my machine, GPT4All stands out for several reasons:
- Open-Source: Being open-source, it offers transparency and the freedom to modify as per individual requirements.
- Ease of Use: With just a few lines of code, you can have a GPT-like model up and running.
- Downloadable Models: The platform provides direct links to download models, eliminating the need to search elsewhere.
- No API Costs: While many platforms charge for API usage, GPT4All allows you to run models without incurring additional costs.
Setting Up GPT4All on Python
Here's a quick guide on how to set up and run a GPT-like model using GPT4All on python.
I highly recommend to create a virtual environment if you are going to use this for a project. In this article you can look how to set up a virtual environment in python .
first install the libraries needed:
pip install langchain, gpt4all
I used this versions gpt4all-1.0.12 , langchain-0.0.296
Then you need to download the models that you want to try. In the same web page provided before (just scroll a little bit more). I recomend this two models if you have 16GB or more in RAM.

Sample Code and Response
Here's the code I used (all credits to this youtube short video of Nicholas Renotte )
Import dependencies\
from langchain import PromptTemplate, LLMChain\
from langchain.llms import GPT4All
Specify model weights path\
PATH='./nous-hermes-13b.ggmlv3.q4_0.bin'
Create LLM Class\
llm = GPT4All(model=PATH, verbose=True)
Create a prompt template\
prompt = PromptTemplate(\
input_variables=['instruction', 'input', 'response'],\
template="""\
Instruction:\
{instruction}\
### Input:\
{input}\
### Response:\
{response}\
""" )chain = LLMChain(prompt=prompt, llm=llm)
Run the prompt\
I used a childen story to test https://cuentosparadormir.com/infantiles/cuento/barba-flamenco-y-el-recortador-de-cuentos\
its about 783 words long!\
chain.run(instruction="""Resume esta historia, hazlo en español""",\
input="""[...story content...]""",\
response='A: ')
The model's response was insightful, but took 7 minutes to my computer. From a 783 words long input prompt to 75 words long summary, not bad!:
"No hay duda de que el papá aprendió una valiosa lección sobre la importancia de contar los cuentos completos y sin recortes para sus hijos. Al final, descubrió que era mucho más importante mantener la tradición familiar que ahorrarse unos minutos de tiempo. Aunque el viaje por el mundo de los cuentos fue peligroso e impredecible, el papá se dio cuenta de que las historias son un tesoro que no debe ser desperdiciado ni recortado."
It's really impresive comparing it to other models that i used before on hugging face.
The Power of Instruction and Input
At the heart of GPT4All's functionality lies the instruction and input segments. These segments dictate the nature of the response generated by the model. The instruction provides a directive to the model, guiding its thought process. For instance, in the code provided, the instruction is to "Resume esta historia, hazlo en español" (Summarize this story, do it in Spanish). This tells the model the desired action and the language preference.
The input, on the other hand, is the content you wish the model to process. In our case, it's a captivating tale of a father's adventurous journey through a storybook world. The richness and length of the input directly influence the processing time.
Performance Insights
It's essential to understand that the length and complexity of the prompt and instruction can impact the processing time. In my experiments, I aimed to use GPT4All to summarize extensive texts, including those in Spanish. I tested the model with a story sourced from a children's story webpage. While the results were promising, the summary was slightly lengthy, taking about 7 minutes to process on a notebook equipped with a 3070 RTX, i9, and 32 GB RAM. Anyways i also tried shorter and easier tasks in english and it works just like a ChatGPT (arguibly better cause it doesn't have censorchip in several models!)
This experience underscores the importance of fine-tuning the model and instructions for optimal performance. While the initial results were satisfactory, achieving efficiency might require multiple iterations.
Hardware Considerations
One of the standout features of GPT4All is its adaptability to various hardware configurations. While my notebook boasts high-end specifications, GPT4All can be easily implemented on any system with a decent hardware level. This flexibility makes it an attractive option for a wide range of users.
GUI Interface Alternative
If you want to interact directly with the interface like it was Chat GPT you can download it on an GUI interface , where you can choose and download the models you want to try (there are plenty to choose depeding on you computer capacity). And then interact with that interface like it was chat gpt (and even customize the window).
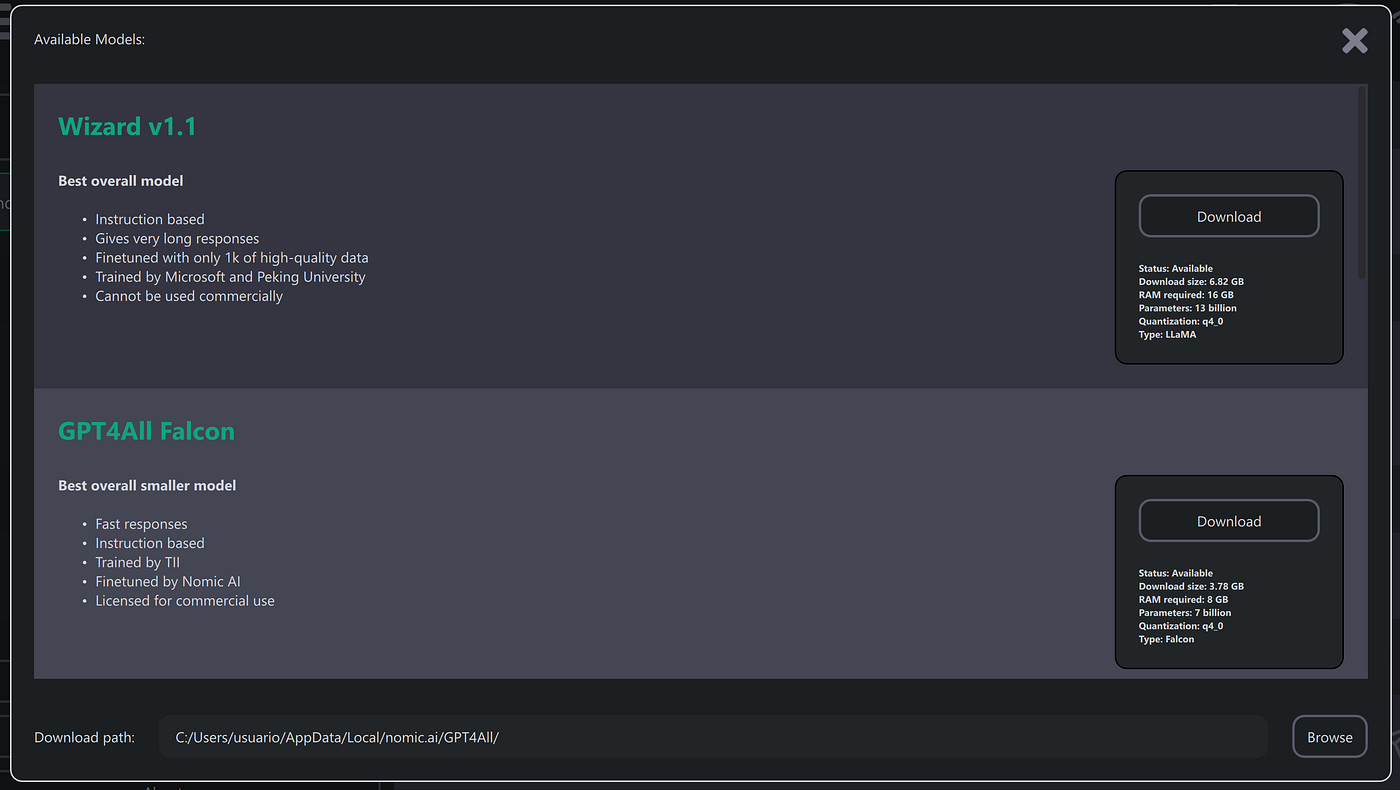
Downloads interface
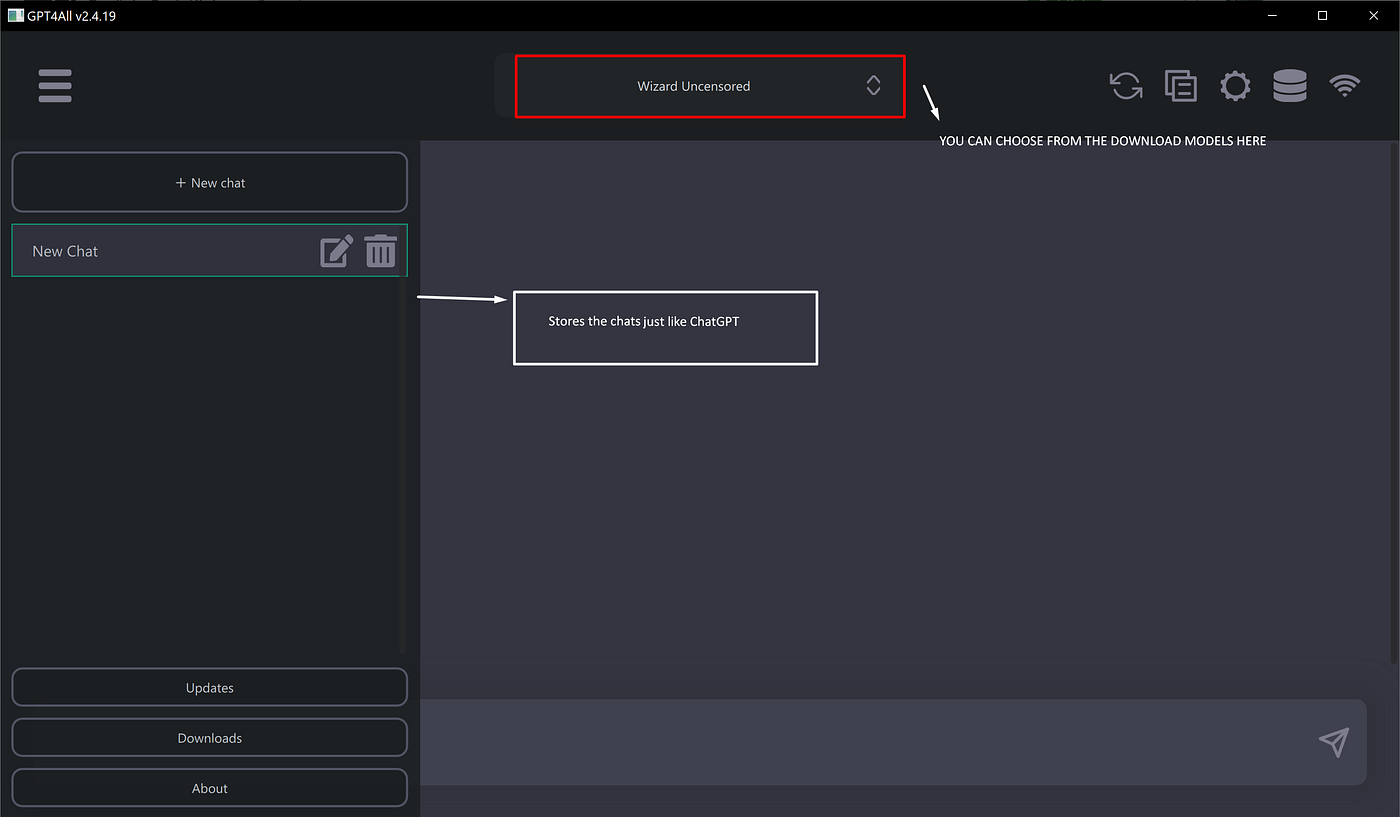
Chat Interface
My Experience
Before discovering GPT4All, I spent countless hours trying to set up Llama2. The process was cumbersome, and I faced multiple roadblocks. In contrast, GPT4All offered a breath of fresh air. The entire setup was completed in minutes, and I was able to run GPT-like models without any hiccups.
Conclusion
In the ever-evolving world of AI, tools like GPT4All are a boon. They simplify the process, save time, and allow enthusiasts and professionals alike to focus on what truly matters: building and experimenting. If you've been struggling with setting up GPT-like models on your machine, I highly recommend giving GPT4All a try. It's been the easiest solution I've tried so far, and I'm sure you'll feel the same.
Build a Fault-tolerant REDIS Sentinel Cluster
Today, Im going to show you how to setup a fault-tolerant master/slave redis cluster using sentinel to failover lost nodes.
Redis is a very versatile database, but what if you want to run it on a cluster? A lot of times, people will run redis as a standalone server with no backup. But what happens when that machine goes down? Or what if we want to migrate our redis instance to a new machine without downtime?
All of this is possible by creating a replica set (master node and n many slave nodes) and letting sentinel watch and manage them. If sentinel discovers that a node has disappeared, it will attempt to elect a new master node, provided that a majority of sentinels in the cluster agree (i.e. quorum).
The quorum is the number of Sentinels that need to agree about the fact the master is not reachable, in order for really mark the slave as failing, and eventually start a fail over procedure if possible.
However the quorum is only used to detect the failure. In order to actually perform a failover, one of the Sentinels need to be elected leader for the failover and be authorized to proceed. This only happens with the vote of the majority of the Sentinel processes.
In this particular example, we're going to setup our nodes in a master/slave configuration, where we will have 1 master and 2 slave nodes. This way, if we lose one node, the cluster will still retain quorum and be able to elect a new master. In this setup, writes will have to go through the master as slaves are read-only. The upside to this is that if the master disappears, its entire state has already been replicated to the slave nodes, meaning when one is elected as master, it can being to accept writes immediately. This is different than setting up a redis cluster where data is sharded across master nodes rather than replicated entirely.
Since sentinel handles electing a master node and sentinel nodes communicate with each other, we can use it as a discovery mechanism to determine which node is the master and thus where we should send our writes.
Setup
To set up a cluster, we're going to run 3 redis instances:
- 1 master
- 2 slaves
Each of the three instances will also have a redis sentinel server running along side it for monitoring/service discovery. The config files I have for this example can be run on your localhost, or you can change the IP addresses to fit your own use-case. All of this will be done using version 3.0.2 of redis.
Configs
If you dont feel like writing configs by hand, you can clone the example repository I have at github.com/seanmcgary/redis-cluster-example. In there, you'll find a directory structure that looks like this:
redis-cluster
â"œâ"€â"€ node1
â"‚  â"œâ"€â"€ redis.conf
â"‚  â""â"€â"€ sentinel.conf
â"œâ"€â"€ node2
â"‚  â"œâ"€â"€ redis.conf
â"‚  â""â"€â"€ sentinel.conf
â""â"€â"€ node3
â"œâ"€â"€ redis.conf
â""â"€â"€ sentinel.conf
3 directories, 6 filesFor the purpose of this demo, node1 will be our starting master node and nodes 2 and 3 will be added as slaves.
Master node config
redis.conf
bind 127.0.0.1
port 6380
dir .sentinel.conf
# Host and port we will listen for requests onbind 127.0.0.1port 16380## "redis-cluster" is the name of our cluster## each sentinel process is paired with a redis-server process#sentinel monitor redis-cluster 127.0.0.1 6380 2sentinel down-after-milliseconds redis-cluster 5000sentinel parallel-syncs redis-cluster 1sentinel failover-timeout redis-cluster 10000Our redis config should be pretty self-explainatory. For the sentinel config, we've chosen the redis-server port + 10000 to keep things somewhat consistent and make it easier to see which sentinel config goes with which server.
sentinel monitor redis-cluster 127.0.0.1 6380 2The third "argument" here is the name of our cluster. Each sentinel server needs to have the same name and will point at the master node (rather than the redis-server it shares a host with). The final argument (2 here) is how many sentinel nodes are required for quorum when it comes time to vote on a new master. Since we have 3 nodes, we're requiring a quorum of 2 sentinels, allowing us to lose up to one machine. If we had a cluster of 5 machines, which would allow us to lose 2 machines while still maintaining a majority of nodes participating in quorum.
sentinel down-after-milliseconds redis-cluster 5000For this example, a machine will have to be unresponsive for 5 seconds before being classified as down thus triggering a vote to elect a new master node.
Slave node config
Our slave node configs don't look much different. This one happens to be for node2:
redis.conf
bind 127.0.0.1
port 6381
dir .
slaveof 127.0.0.1 6380sentinel.conf
# Host and port we will listen for requests onbind 127.0.0.1port 16381## "redis-cluster" is the name of our cluster## each sentinel process is paired with a redis-server process#sentinel monitor redis-cluster 127.0.0.1 6380 2sentinel down-after-milliseconds redis-cluster 5000sentinel parallel-syncs redis-cluster 1sentinel failover-timeout redis-cluster 10000The only difference is this line in our redis.conf:
slaveof 127.0.0.1 6380In order to bootstrap the cluster, we need to tell the slaves where to look for a master node. After the initial bootstrapping process, redis will actually take care of rewriting configs as we add/remove nodes. Since we're not really worrying about deploying this to a production environment where addresses might be dynamic, we're just going to hardcode our master node's IP address and port.
We're going to do the same for the slave sentinels as well as we want them to monitor our master node (node1).
Starting the cluster
You'll probably want to run each of these in something like screen or tmux so that you can see the output from each node all at once.
Starting the master node
redis-server, node1
$ redis-server node1/redis.conf
57411:M 07 Jul 16:32:09.876 * Increased maximum number of open files to 10032 (it was originally set to 256).
_.__.-``__ ''-.__.-`` `. `_. ''-._ Redis 3.0.2 (01888d1e/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6380
| `-._ `._ / _.-' | PID: 57411
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
57411:M 07 Jul 16:32:09.878 # Server started, Redis version 3.0.257411:M 07 Jul 16:32:09.878 * DB loaded from disk: 0.000 seconds
57411:M 07 Jul 16:32:09.878 * The server is now ready to accept connections on port 6380sentinel, node1
$ redis-server node1/sentinel.conf --sentinel
57425:X 07 Jul 16:32:33.794 * Increased maximum number of open files to 10032 (it was originally set to 256).
_.__.-``__ ''-.__.-`` `. `_. ''-._ Redis 3.0.2 (01888d1e/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 16380
| `-._ `._ / _.-' | PID: 57425
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
57425:X 07 Jul 16:32:33.795 # Sentinel runid is dde8956ca13c6b6d396d33e3a47ab5b489fa3292
57425:X 07 Jul 16:32:33.795 # +monitor master redis-cluster 127.0.0.1 6380 quorum 2Starting the slave nodes
Now we can go ahead and start our slave nodes. As you start them, you'll see the master node report as they come online and join.
redis-server, node2
$ redis-server node2/redis.conf57450:S 07 Jul 16:32:57.969 * Increased maximum number of open files to 10032 (it was originally set to 256)._.__.-``__ ''-.__.-`` `. `_. ''-._ Redis 3.0.2 (01888d1e/0) 64 bit.-`` .-```. ```\/ _.,_ ''-._( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6381| `-._ `._ / _.-' | PID: 57450`-._ `-._ `-./ _.-' _.-'|`-._`-._ `-.__.-' _.-'_.-'|| `-._`-._ _.-'_.-' | http://redis.io`-._ `-._`-.__.-'_.-' _.-'|`-._`-._ `-.__.-' _.-'_.-'|| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
57450:S 07 Jul 16:32:57.971 # Server started, Redis version 3.0.257450:S 07 Jul 16:32:57.971 * DB loaded from disk: 0.000 seconds57450:S 07 Jul 16:32:57.971 * The server is now ready to accept connections on port 638157450:S 07 Jul 16:32:57.971 * Connecting to MASTER 127.0.0.1:638057450:S 07 Jul 16:32:57.971 * MASTER <-> SLAVE sync started57450:S 07 Jul 16:32:57.971 * Non blocking connect for SYNC fired the event.57450:S 07 Jul 16:32:57.971 * Master replied to PING, replication can continue...57450:S 07 Jul 16:32:57.971 * Partial resynchronization not possible (no cached master)57450:S 07 Jul 16:32:57.971 * Full resync from master: d75bba9a2f3c5a6e2e4e9dfd70ddb0c2d4e647fd:157450:S 07 Jul 16:32:58.038 * MASTER <-> SLAVE sync: receiving 18 bytes from master57450:S 07 Jul 16:32:58.038 * MASTER <-> SLAVE sync: Flushing old data57450:S 07 Jul 16:32:58.038 * MASTER <-> SLAVE sync: Loading DB in memory57450:S 07 Jul 16:32:58.038 * MASTER <-> SLAVE sync: Finished with successsentinel, node2
$ redis-server node2/sentinel.conf --sentinel
_.__.-``__ ''-.__.-`` `. `_. ''-._ Redis 3.0.2 (01888d1e/0) 64 bit
.-`` .-```. ```\/ _.,_ ''-._
( ' , .-` | `, ) Running in sentinel mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 16381
| `-._ `._ / _.-' | PID: 57464
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'57464:X 07 Jul 16:33:18.109 # Sentinel runid is 978afe015b4554fdd131957ef688ca4ec3651ea157464:X 07 Jul 16:33:18.109 # +monitor master redis-cluster 127.0.0.1 6380 quorum 257464:X 07 Jul 16:33:18.111 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ redis-cluster 127.0.0.1 638057464:X 07 Jul 16:33:18.205 * +sentinel sentinel 127.0.0.1:16380 127.0.0.1 16380 @ redis-cluster 127.0.0.1 6380Go ahead and do the same for node3.
If we look at the log output for node1's sentinel, we can see that the slaves have been added:
57425:X 07 Jul 16:33:03.895 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ redis-cluster 127.0.0.1 638057425:X 07 Jul 16:33:20.171 * +sentinel sentinel 127.0.0.1:16381 127.0.0.1 16381 @ redis-cluster 127.0.0.1 638057425:X 07 Jul 16:33:44.107 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ redis-cluster 127.0.0.1 638057425:X 07 Jul 16:33:44.303 * +sentinel sentinel 127.0.0.1:16382 127.0.0.1 16382 @ redis-cluster 127.0.0.1 6380Find the master node
Now that our cluster is in place, we can ask sentinel which node is currently set as the master. To illustrate this, we'll ask sentinel on node3:
$ redis-cli -p 16382 sentinel get-master-addr-by-name redis-cluster
1) "127.0.0.1"
2) "6380"As we can see here, the ip and port values match our node1 which is our master node that we started.
Electing a new master
Now lets kill off our original master node
$ redis-cli -p 6380 debug segfaultLooking at the logs from node2's sentinel we can watch the new master election happen:
57464:X 07 Jul 16:35:30.270 # +sdown master redis-cluster 127.0.0.1 638057464:X 07 Jul 16:35:30.301 # +new-epoch 157464:X 07 Jul 16:35:30.301 # +vote-for-leader 2a4d7647d2e995bd7315d8358efbd336d7fc79ad 157464:X 07 Jul 16:35:30.330 # +odown master redis-cluster 127.0.0.1 6380 #quorum 3/257464:X 07 Jul 16:35:30.330 # Next failover delay: I will not start a failover before Tue Jul 7 16:35:50 201557464:X 07 Jul 16:35:31.432 # +config-update-from sentinel 127.0.0.1:16382 127.0.0.1 16382 @ redis-cluster 127.0.0.1 638057464:X 07 Jul 16:35:31.432 # +switch-master redis-cluster 127.0.0.1 6380 127.0.0.1 638157464:X 07 Jul 16:35:31.432 * +slave slave 127.0.0.1:6382 127.0.0.1 6382 @ redis-cluster 127.0.0.1 638157464:X 07 Jul 16:35:31.432 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ redis-cluster 127.0.0.1 638157464:X 07 Jul 16:35:36.519 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ redis-cluster 127.0.0.1 6381Now, lets see which machine got elected:
$ redis-cli -p 16382 sentinel get-master-addr-by-name redis-cluster
1) "127.0.0.1"
2) "6381"Here, we can see that node2 has been elected the new master of the cluster. Now, we can restart node1 and you'll see it come back up as a slave since node2 has been elected as the master node.
$ redis-server node1/redis.conf
57531:M 07 Jul 16:37:24.176 # Server started, Redis version 3.0.257531:M 07 Jul 16:37:24.176 * DB loaded from disk: 0.000 seconds
57531:M 07 Jul 16:37:24.176 * The server is now ready to accept connections on port 638057531:S 07 Jul 16:37:34.215 * SLAVE OF 127.0.0.1:6381 enabled (user request)
57531:S 07 Jul 16:37:34.215 # CONFIG REWRITE executed with success.
57531:S 07 Jul 16:37:34.264 * Connecting to MASTER 127.0.0.1:638157531:S 07 Jul 16:37:34.264 * MASTER <-> SLAVE sync started
57531:S 07 Jul 16:37:34.265 * Non blocking connect for SYNC fired the event.
57531:S 07 Jul 16:37:34.265 * Master replied to PING, replication can continue...
57531:S 07 Jul 16:37:34.265 * Partial resynchronization not possible (no cached master)
57531:S 07 Jul 16:37:34.265 * Full resync from master: 135e2c6ec93d33dceb30b7efb7da171b0fb93b9d:2475657531:S 07 Jul 16:37:34.276 * MASTER <-> SLAVE sync: receiving 18 bytes from master
57531:S 07 Jul 16:37:34.276 * MASTER <-> SLAVE sync: Flushing old data
57531:S 07 Jul 16:37:34.276 * MASTER <-> SLAVE sync: Loading DB in memory
57531:S 07 Jul 16:37:34.276 * MASTER <-> SLAVE sync: Finished with success
That's it! This was a pretty simple example and is meant to introduce how you can setup a redis replica cluster with failover. In a followup post, I'll show how you can implement this on an actual cluster with CoreOS, containers, and HAProxy for loadbalancing.
Redis High Availability Architecture with Sentinel
Redis Sentinel is a dedicated process to automate and simplify the Redis replication failover and switchover. Without Sentinel, you could also manage your Redis replication manually, by using the SLAVEOF or REPLICAOF command. Sentinel requires a number of instances, and works as a group of decision-makers, before deciding which node is up or down and when the failover should be triggered. In simple words, Sentinel is the replication failover manager for Redis.
In this example, we are going to deploy a simple highly available Redis architecture with Sentinel, as illustrated in the following diagram:
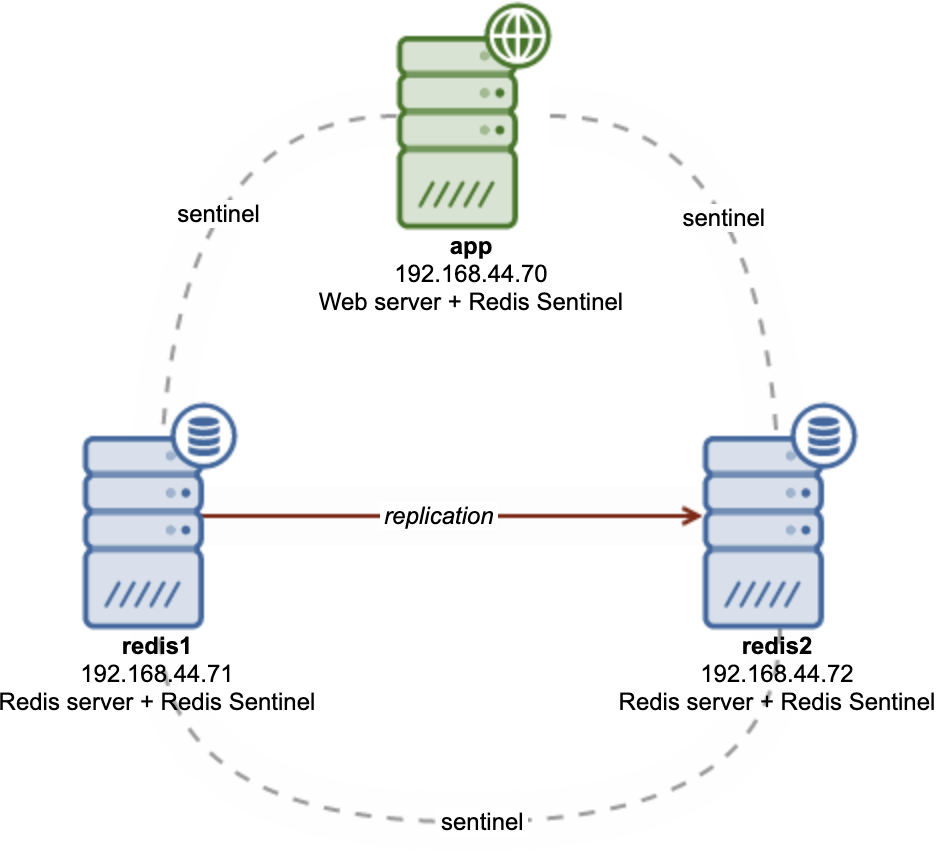
We will have two Redis instances on two different nodes -- 1 master and 1 replica (or slave). Sentinel will be co-located on those 2 nodes, plus an additional node on one of our web servers.
Redis Replication Deployment
Commonly, one would co-locate a Redis instance on the web/application server and access it via localhost or through a UNIX socket file. This can be considered the most straightforward way to incorporate Redis into the application.
For a scalable and highly available setup app, Redis should be deployed in a centralized approach, or into a different tier called a cache tier. This allows Redis instances to work together as a dedicated cache provider for the applications, decoupling the applications from the local Redis dependencies.
Before deploying Redis Sentinel, we have to deploy a Redis replication consisting of two or more Redis instances. Let's start by installing Redis on both servers, redis1 and redis2:
sudo add-apt-repository ppa:redislabs/redis
sudo apt-get -y update
sudo apt-get -y install redis redis-sentinel net-toolsNext, we need to make sure the following configuration lines exist inside /etc/redis/redis.conf:
For redis1 (master):
bind 127.0.0.1 192.168.44.71
protected-mode no
supervised systemd
masterauth SuperS3cr3tP455
masteruser masteruser
user masteruser +@all on >SuperS3cr3tP455For redis2 (replica):
bind 127.0.0.1 192.168.44.72
protected-mode no
supervised systemd
replicaof 192.168.44.71 6379
masterauth SuperS3cr3tP455
masteruser masteruser
user masteruser +@all on >SuperS3cr3tP455Some explanations:
-
bind: List all the IP addresses that you want Redis to listen to. For Sentinel to work properly, Redis must be reachable remotely. Therefore we have to list out the interface the Sentinel will communicate with.
-
protected-mode: This must be set to "no" to allow Redis to serve remote connections. This is required for Sentinel as well.
-
supervised: We use the default systemd unit files provided by the installer package. For Ubuntu 20.04, it uses systemd as the service manager so we specify systemd here.
-
replicaof: This is only for the slave node. For the original topology, we will make redis2 as the replica and redis1 as the master.
-
masterauth: The password for user masteruser.
-
masteruser: The username of the master user.
-
user: We create the master user here. The user shall have no limit (+@all) and a password. This user will be used for Redis to manage replication and failover by Sentinel.
Restart Redis to apply the changes and enable it on boot:
$ sudo systemctl restart redis-server
$ sudo systemctl enable redis-serverVerify that Redis is running on port 6379 on both interfaces. The following example is the output from redis2:
$ sudo netstat -tulpn | grep -i redis
tcp 0 0 192.168.44.72:6379 0.0.0.0:* LISTEN 15992/redis-server
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 15992/redis-serverVerify the replication is working. On redis1:
(redis1) $ redis-cli info replication
# Replication
role:master
connected_slaves:1
slave0_ip=192.168.44.72,port=6379,state=online,offset=154,lag=1
master_failover_state:no-failover
master_replid:e1a86d60fe42b41774f186528661ea6b8fc1d97a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:154
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:154Pay attention to the role, connected_slaves and slave{i} keys. This indicates that redis1 is the master. Also, note that a replica can be a master of another replica -- this is also known as chained replication.
While on the redis2:
(redis2) $ redis-cli info replication
# Replication
role:slave
master_host:192.168.44.71
master_port:6379
master_link_status:up
master_last_io_seconds_ago:2
master_sync_in_progress:0
slave_repl_offset:140
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:e1a86d60fe42b41774f186528661ea6b8fc1d97a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:140
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:140Pay attention to the role, master_host, master_link_status and master_repl_offset. The replication delay between these two nodes can be determined by the master_repl_offset value on both servers.
Redis Sentinel Deployment
Redis Sentinel is basically the same redis-server process running with the "--sentinel" flag and different configuration files and ports. For production usage, it is strongly recommended to have at least 3 Sentinel instances for an accurate observation when performing the automatic failover. Therefore, we will install Sentinel on those 2 Redis nodes that we have, plus one of our web servers, 192.168.44.70 (shown in the architecture diagram).
Install the redis-sentinel package on the selected web server (Sentinel is already installed on our Redis hosts):
$ sudo add-apt-repository ppa:redislabs/redis
$ sudo apt-get -y update
$ sudo apt-get -y install redis-sentinel net-toolsBy default, the Sentinel configuration file is located at /etc/redis/sentinel.conf. Make sure the following configuration lines are set:
App server, 192.168.44.70:
bind 192.168.44.70
port 26379
sentinel monitor mymaster 192.168.44.71 6379 2
sentinel auth-pass mymaster SuperS3cr3tP455
sentinel auth-user mymaster masteruser
sentinel down-after-milliseconds mymaster 10000redis1, 192.168.44.71:
bind 192.168.44.71
port 26379
sentinel monitor mymaster 192.168.44.71 6379 2
sentinel auth-pass mymaster SuperS3cr3tP455
sentinel auth-user mymaster masteruser
sentinel down-after-milliseconds mymaster 10000redis2, 192.168.44.72:
bind 192.168.44.72
port 26379
sentinel monitor mymaster 192.168.44.71 6379 2
sentinel auth-pass mymaster SuperS3cr3tP455
sentinel auth-user mymaster masteruser
sentinel down-after-milliseconds mymaster 10000Restart the redis-sentinel daemon to apply the changes:
$ sudo systemctl restart redis-sentinel
$ sudo systemctl enable redis-sentinelMake sure redis-sentinel is running on port 26379. On redis2, you should see something like this:
$ sudo netstat -tulpn | grep -i redis
tcp 0 0 192.168.44.72:26379 0.0.0.0:* LISTEN 20093/redis-sentine
tcp 0 0 192.168.44.72:6379 0.0.0.0:* LISTEN 15992/redis-server
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 15992/redis-serverVerify if the Sentinel is observing our Redis replication link by looking at the log file, /var/log/redis/redis-sentinel.log. Make sure you see the following lines:
20093:X 19 Jun 2021 12:06:39.780 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
20093:X 19 Jun 2021 12:06:39.780 # Redis version=6.2.4, bits=64, commit=00000000, modified=0, pid=20093, just started
20093:X 19 Jun 2021 12:06:39.780 # Configuration loaded
20093:X 19 Jun 2021 12:06:39.781 * monotonic clock: POSIX clock_gettime
20093:X 19 Jun 2021 12:06:39.781 * Running mode=sentinel, port=26379.
20093:X 19 Jun 2021 12:06:39.784 # Sentinel ID is 0f84e662fc3dd580721ce56f6a409e0f70ed341c
20093:X 19 Jun 2021 12:06:39.784 # +monitor master mymaster 192.168.44.71 6379 quorum 2
20093:X 19 Jun 2021 12:06:39.786 * +slave slave 192.168.44.72:6379 192.168.44.72 6379 @ mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 12:06:41.163 * +sentinel sentinel 6484e8281246c950d31e779a564c29d7c43aa68c 192.168.44.71 26379 @ mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 12:07:20.205 * +sentinel sentinel 727151aabca8596dcc723e6d1176f8aa01203ada 192.168.44.70 26379 @ mymaster 192.168.44.71 6379We can get more information on the Sentinel process by using the redis-cli and connect to the Sentinel port 26379:
(app)$ redis-cli -h 192.168.44.72 -p 26379 sentinel masters
1) 1) "name"
2) "mymaster"
3) "ip"
4) "192.168.44.71"
5) "port"
6) "6379"
7) "runid"
8) "a9158eb1d25a8291b3808e5ddfe87bd24cceb550"
9) "flags"
10) "master"
11) "link-pending-commands"
12) "0"
13) "link-refcount"
14) "1"
15) "last-ping-sent"
16) "0"
17) "last-ok-ping-reply"
18) "80"
19) "last-ping-reply"
20) "80"
21) "down-after-milliseconds"
22) "10000"
23) "info-refresh"
24) "10063"
25) "role-reported"
26) "master"
27) "role-reported-time"
28) "90348"
29) "config-epoch"
30) "0"
31) "num-slaves"
32) "1"
33) "num-other-sentinels"
34) "2"
35) "quorum"
36) "2"
37) "failover-timeout"
38) "180000"
39) "parallel-syncs"
40) "1"Pay attention to the "num-slaves" value which is 1 and "num-other-sentinels" value which is 2, indicating that we have a total number of 3 Sentinel nodes (one for this node + two other nodes). At this point, our Redis Sentinel configuration is complete.
Failover Testing
We can now test the failover by simply shutting down the Redis service on redis1(master):
$ sudo systemctl stop redis-serverAfter 10 seconds (down-after-milliseconds value), you should see the following output in the /var/log/redis/redis-sentinel.log file:
20093:X 19 Jun 2021 13:07:43.581 # +sdown master mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:43.644 # +odown master mymaster 192.168.44.71 6379 #quorum 2/2
20093:X 19 Jun 2021 13:07:43.644 # +new-epoch 1
20093:X 19 Jun 2021 13:07:43.645 # +try-failover master mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:43.646 # +vote-for-leader 0f84e662fc3dd580721ce56f6a409e0f70ed341c 1
20093:X 19 Jun 2021 13:07:43.650 # 6484e8281246c950d31e779a564c29d7c43aa68c voted for 0f84e662fc3dd580721ce56f6a409e0f70ed341c 1
20093:X 19 Jun 2021 13:07:43.651 # 727151aabca8596dcc723e6d1176f8aa01203ada voted for 0f84e662fc3dd580721ce56f6a409e0f70ed341c 1
20093:X 19 Jun 2021 13:07:43.705 # +elected-leader master mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:43.705 # +failover-state-select-slave master mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:43.758 # +selected-slave slave 192.168.44.72:6379 192.168.44.72 6379 @ mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:43.758 * +failover-state-send-slaveof-noone slave 192.168.44.72:6379 192.168.44.72 6379 @ mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:43.842 * +failover-state-wait-promotion slave 192.168.44.72:6379 192.168.44.72 6379 @ mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:44.728 # +promoted-slave slave 192.168.44.72:6379 192.168.44.72 6379 @ mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:44.728 # +failover-state-reconf-slaves master mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:44.827 # +failover-end master mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:07:44.827 # +switch-master mymaster 192.168.44.71 6379 192.168.44.72 6379
20093:X 19 Jun 2021 13:07:44.827 * +slave slave 192.168.44.71:6379 192.168.44.71 6379 @ mymaster 192.168.44.72 6379
20093:X 19 Jun 2021 13:07:54.874 # +sdown slave 192.168.44.71:6379 192.168.44.71 6379 @ mymaster 192.168.44.72 6379At this point, our only slave, 192.168.44.72, has been promoted to a master. Once our old master (redis1) comes back online, you should see something like this reported by Sentinel:
20093:X 19 Jun 2021 13:10:23.859 * +convert-to-slave slave 192.168.44.71:6379 192.168.44.71 6379 @ mymaster 192.168.44.72 6379The above indicates the old master has been converted to slave and now replicating from the current master, redis2. We can confirm this by checking the replication info on redis2:
(redis2)$ redis-cli info replication
# Replication
role:master
connected_slaves:1
slave0_ip=192.168.44.71,port=6379,state=online,offset=1041068,lag=1
master_failover_state:no-failover
master_replid:9db31b3b1010100cf187a316cfdf7ed92577e60f
master_replid2:e1a86d60fe42b41774f186528661ea6b8fc1d97a
master_repl_offset:1041350
second_repl_offset:991011
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1041350If we want to promote redis1 to a master status again, we can simply bring down redis2 or use the Sentinel failover command as below:
(app)$ redis-cli -h 192.168.44.70 -p 26379 sentinel failover mymaster
OKOnce the failover is triggered, Sentinel will report the master promotion as below:
20093:X 19 Jun 2021 13:13:34.608 # +new-epoch 2
20093:X 19 Jun 2021 13:13:35.716 # +config-update-from sentinel 727151aabca8596dcc723e6d1176f8aa01203ada 192.168.44.70 26379 @ mymaster 192.168.44.72 6379
20093:X 19 Jun 2021 13:13:35.716 # +switch-master mymaster 192.168.44.72 6379 192.168.44.71 6379
20093:X 19 Jun 2021 13:13:35.717 * +slave slave 192.168.44.72:6379 192.168.44.72 6379 @ mymaster 192.168.44.71 6379
20093:X 19 Jun 2021 13:13:45.756 * +convert-to-slave slave 192.168.44.72:6379 192.168.44.72 6379 @ mymaster 192.168.44.71 6379The former slave, redis1, has been promoted as the new master (+switch-master) and redis2 has been converted to slave (+convert-to-slave). We are now back to the original topology as we started.
Final Thoughts
Redis Sentinel is a must-have tool if you want a highly available Redis replication setup. It simplifies and automates the replication failover and switchover for Redis and it is fairly easy to set up. However, if you are not using Redis and since we have also mentioned database nodes, your database infrastructure including database nodes can also be monitored by using ClusterControl.
Docker -- How to use Docker with HAProxy+Keepalived
I want to practice in creation of high-available web-application using multiple Docker containers on one machine.
I launch several web-servers within Docker containers. Say, three servers rest1, rest2 and rest3.
I use Docker with HAProxy balancer, which is binded to 127.0.0.1:80 and routes queries to rest servers. This allows me to be sure, that when one or two rest servers failed, I will be able to make queries to 127.0.0.1:80 and receive correct results.
The bad thing is: when HAProxy is down, web-application is down.
I want to use several HAProxy Docker containers with Keepalived service in each container.\
The problem is: I need several Docker containers to listen to one IP and one PORT. E.g., I will have haproxy1 and haproxy2, which will be binded to localhost via Keepalived.
When I set IP in HAProxy configuration file, which is not an IP of current Docker container, it shows me an error, that HAProxy cannot listen this IP and PORT.
Is it possible to configure multiple Docker containers with HAProxy and Keepalived to listen to one IP and PORT?
Configuration of HAProxy:
defaults
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend http-in
mode http
bind 172.17.0.10:80
default_backend BACKEND
backend BACKEND
option httpchk
server rest1 rest1:8080 maxconn 32 check
server rest2 rest2:8080 maxconn 32 check
server rest3 rest3:8080 maxconn 32 check
fails with error
Starting frontend http-in: cannot bind socket [172.17.0.10:80]
172.17.0.10 is a member of Docker subnetwork and not reserved on my machine.
Best Answer
You may need to enable non-local binding on the docker host.
Add net.ipv4.ip_nonlocal_bind=1 to the end of the /etc/sysctl.conf file and force a reload of the file with the sudo sysctl -p command.
Related Solutions
HAProxy -- ssl client ca chain cannot be verified
The files server.pem and client.pem should have 3 sections in it and should look like this:
-----BEGIN RSA PRIVATE KEY-----
<lots of base64 encoded data>
-----END RSA PRIVATE KEY-----
-----BEGIN CERTIFICATE-----
<lots of base64 encoded data>
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
<lots of base64 encoded data>
-----END CERTIFICATE-----
The private key might not be RSA, but it should be first. The first certificate is the signed server certificate. The second certificate should be the CA certificate. You can copy and paste each section using a text editor. To check your certificate, run this.
$ openssl verify -CAfile ca1-certificate.pem server.pem
server.pem: OK
Haproxy logging not work
To have these messages end up in - for example - /var/log/haproxy.log you will need to do two things:
- configure your syslog to accept network logs - at least on localhost
- configure haproxy to send events to 127.0.0.1 on local2/local3 or any such facility
So, your haproxy.cfgs global section would look something like:
global
log 127.0.0.1 local2 notice
log 127.0.0.1 local3
While your syslog.conf should look like:
local2.* /var/log/haproxy
local3.* /var/log/haproxy-access_log
If you use modern distro with rsyslog, then just create a file called
/etc/rsyslog.d/haproxy.conf
with following contents:
$ModLoad imudp
$UDPServerAddress 127.0.0.1
$UDPServerRun 514
local2.* /var/log/haproxy
local3.* /var/log/haproxy-access_log
And after that restart rsyslogd and haproxy.
Happy Birthday Dad!
Setup a highly-available Redis cluster with Sentinel and HAProxy
Juni 2019
The purpose of this tutorial is to show You how to quickly setup a Redis cluster with Sentinel (comes with Redis) and HAProxy on Ubuntu 18.04
A quick explanation of the technologies used in this tutorial
-
Redis - A fast key/value storage engine
-
Sentinel - Keeps track of Master/Slave machines and promotes and demotes them when VMs go down or go offline
-
HAProxy - A proxy server that can keep track of which services that are available and ready to receive requests
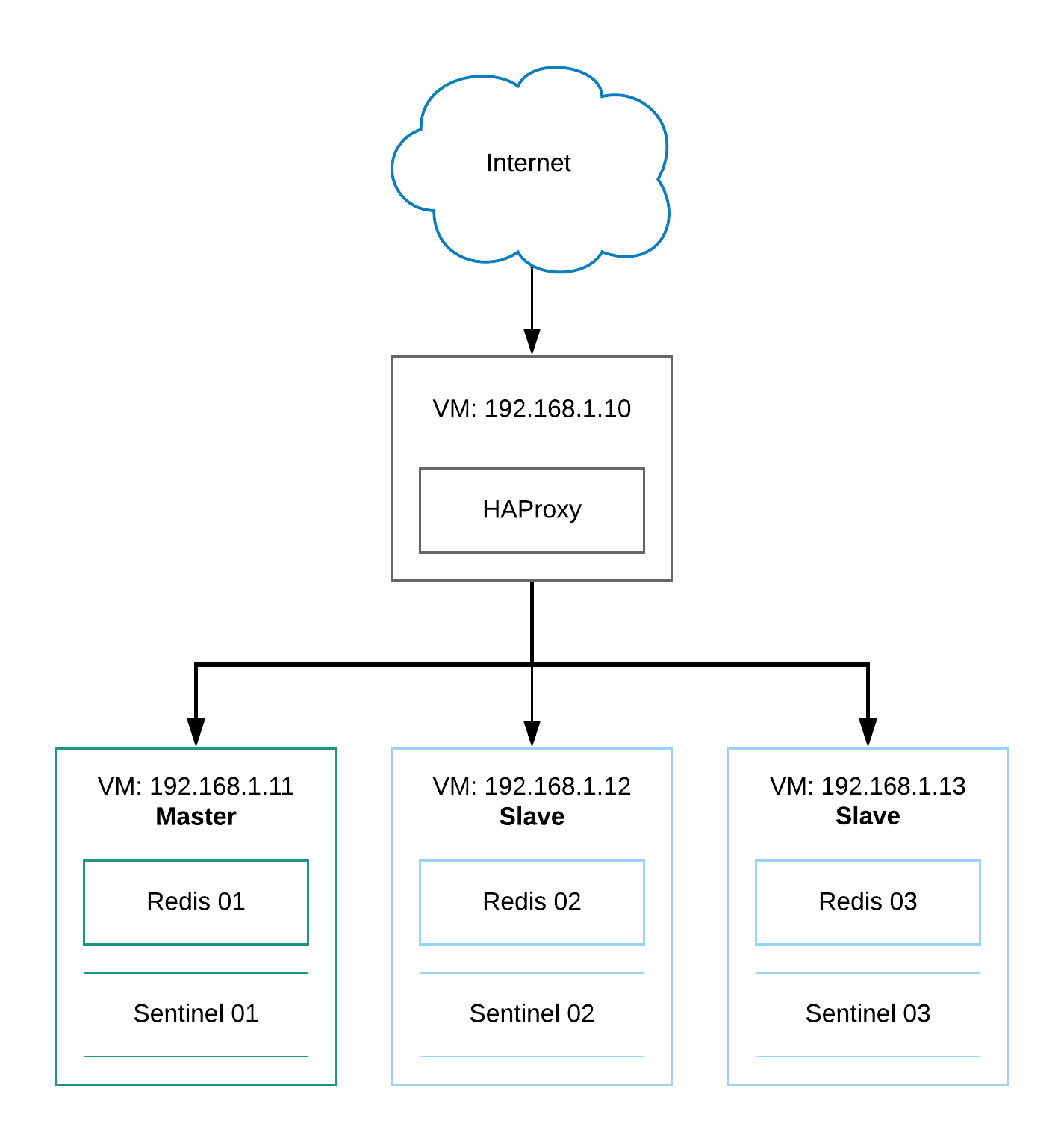
The big picture
Prerequisites
-
For VMs with Ubuntu 18.04 installed
-
Basic knowledge in how to install packages in Ubuntu via APT
-
Basic knowledge of how to edit configuration files
-
Basic knowledge of how firewalls work
Virtual machines
VM Instance | Name | Apps / Services | IP Address\
Instance 01 | haproxy-01 | HAProxy | 192.168.1.10\
Instance 02 | redis-01 | Redis, Sentinel (Master) | 192.168.1.11\
Instance 03 | redis-02 | Redis, Sentinel (Slave) | 192.168.1.12\
Instance 04 | redis-03 | Redis, Sentinel (Slave) | 192.168.1.13
NOTE: Remember that when Sentinel is in charge of deciding which server is Master and Slave. The above stated Master / Slave constellation will change. The table above is a just a snapshot of our initial setup.
1. Install redis-server
`
sudo apt update
sudo apt install redis-server`
Run command below to check that every is working
`
root@redis-example-com-01:~# redis-cli ping
PONG`
2. Install and enable UFW on the machines that will host Redis
`
sudo apt-get update
sudo apt install ufw
sudo ufw enable
sudo ufw allow 22
sudo ufw allow in on eth1 to any port 6379
sudo ufw allow in on eth1 to any port 26379`
In the example above we have allowed traffic on port 22 from everywhere on the internet and we only allow traffic from our private network via our eth1 interface (the interface that has access to our private network) to access our Redis and Sentinel services.
NOTE: Remember to harden Your SSH config in order increase security on machines that are open to traffic from the internet. I would recommend using a jumper machine.
The status of UFW should look something like
`
root@redis-example-com-01:~# ufw status
Status: active
To Action From
-- ------ ----
22 ALLOW Anywhere
6379 on eth1 ALLOW Anywhere
26379 on eth1 ALLOW Anywhere
22 (v6) ALLOW Anywhere (v6)
6379 (v6) on eth1 ALLOW Anywhere (v6)
26379 (v6) on eth1 ALLOW Anywhere (v6)`
The above means that redis and sentinel will only be accessible from the VMs on Your private network.
3. Understand how Master/Slave VMs will talk to each other
Our setup will have three VMs. Below we assume that our private network has the IP format of 192.168.1.XYZ
`
192.168.1.11 ==> Master Node (Initially)
192.168.1.12 ==> Slave Node (Initially)
192.168.1.13 ==> Slave Node (Initially)`
The only difference between our /etc/redis/redis.conf files in our three VMs is that all our slave VMs must have the following 192.168.1.11 as their Master IP address.
Make sure that we are pointing to our Initial Master IP in the /etc/redis/redis.conf of our slave VMs
Add/change config files for Master VM and Slave VMs
There are two config files we need to have per virtual machine
-
/etc/redis/redis.conf
-
/etc/redis/sentinel.conf
Change a few lines in /etc/redis/redis.conf
-
From bind 127.0.0.1 ::1 to # bind 127.0.0.1 ::1, comment out the line (69)
-
From # protected-mode no to protected-mode no, uncomment the line (88) or protected-mode yes to protected-mode no
Only on Slave VMs
Add the line below to replicate data from our VM that has IP 192.168.1.11 in /etc/redis/redis.conf
`
slaveof 192.168.1.11 6379`
And set protected-mode to no in /etc/redis/redis.conf
`
protected-mode no`
NOTE: Replace the IP in the example above with a proper IP from Your private network.
`
slaveof <YOUR_MASTER_IP_HERE> <YOUR_MASTER_PORT_HERE>`
Create a new file in /etc/redis/sentinel.conf and add the lines below
Master (VM: 192.168.1.11)
`
sentinel myid 9862e14b6d9fb11c035c4a28d48573455a7876a2
sentinel monitor redis-primary 192.168.1.11 6379 2
sentinel down-after-milliseconds redis-primary 2000
sentinel failover-timeout redis-primary 5000
protected-mode no`
NOTE: You will find the myid number in Your /etc/redis/sentinel.conf after You have started Sentinel the first time.
The format above is sentinel monitor <NAME> <IP> <PORT> <QUORUM>. Which basically means monitor this Redis node with <IP> and <PORT>, use <NAME> hereafter in the config and at least <QUORUM> (in this case two) sentinels has to agree that this Redis node is down for Sentinel to trigger the promotion of another machine to master in this cluster.
Slave (VM: 192.168.1.12)
`
sentinel myid 9862e14b6d9fb11c035c4a28d48573455a7876a2
sentinel monitor redis-primary 192.168.1.11 6379 2
sentinel down-after-milliseconds redis-primary 2000
sentinel failover-timeout redis-primary 5000
protected-mode no`
Slave (VM: 192.168.1.13)
`
sentinel myid 9862e14b6d9fb11c035c4a28d48573455a7876a2
sentinel monitor redis-primary 192.168.1.11 6379 2
sentinel down-after-milliseconds redis-primary 2000
sentinel failover-timeout redis-primary 5000
protected-mode no`
Ready to fire things up!
You can start/stop/restart the Redis service by running
`
systemctl start|stop|restart|status redis`
-
Keep an eye on the logs to see what is going on under the hood
tail -f /var/log/redis/redis-server.log -
Start a new terminal and run the command below on all three VMs
`
systemctl restart redis`
- Check that Redis is responding properly
`
redis-cli ping`
- Check that the replication is working properly, fire up redis-cli on Your Master VM and set a key in the database named hello and its content to world
`
root@redis-example-com-01:# redis-cli SET hello "world"
OK`
- Fire up new terminals for the Slave VMs and run
`
redis-cli GET hello`
The response should look something like below
`
root@redis-example-com-02:# redis-cli GET hello
"world"`
- Fire up Sentinel
`
redis-server /etc/redis/sentinel.conf --sentinel`
It should give You a detailed log of what is going on what connections are setup between Master and Slave VMs.
Now go to your terminal on Your Master VM and type the command below and see the magic happen.
`
redis-cli -p 6379 DEBUG sleep 30`
If everything is alright, one of the Slave VMs will be promoted to the "New Master". You can query the role of the redis server with the command below
`
redis-cli info replication | grep role`
NOTE: You should run Sentinel as a daemon in production.
Add the lines below to /etc/redis/sentinel.conf if You want to daemonize the Sentinel service on Your production environment.
`
logfile "/var/log/redis/sentinel.log"
daemonize yes`
You can now access the Sentinel logs on a specific VM by running tail -f /var/log/redis/sentinel.log
Run Sentinel as a daemon via systemd
/etc/redis/sentinel.conf
`
sentinel myid 9862e14b6d9fb11c035c4a28d48573455a7876a2
sentinel monitor redis-primary 192.168.1.11 6379 2
sentinel down-after-milliseconds redis-primary 5000
protected-mode no
# Run in production with systemd
logfile "/var/log/redis/sentinel.log"
pidfile "/var/run/redis/sentinel.pid"
daemonize yes`
/etc/systemd/system/sentinel.service
`
[Unit]
Description=Sentinel for Redis
After=network.target
[Service]
Type=forking
User=redis
Group=redis
PIDFile=/var/run/redis/sentinel.pid
ExecStart=/usr/bin/redis-server /etc/redis/sentinel.conf --sentinel
ExecStop=/bin/kill -s TERM $MAINPID
Restart=always
[Install]
WantedBy=multi-user.target`
Change the access permissions of related files
`
sudo chown redis:redis /etc/redis/sentinel.conf
sudo chown redis:redis /var/log/redis/sentinel.log
sudo chmod 640 /etc/redis/sentinel.conf
sudo chmod 660 /var/log/redis/sentinel.log`
Reload and allow Sentinel daemon to autostart
`
sudo systemctl daemon-reload
sudo systemctl enable sentinel.service`
How to start, restart, stop and check status
`
sudo systemctl start|restart|stop|status sentinel`
Setup HAProxy for our cluster
`
sudo apt update
sudo apt install haproxy`
You can check which version You have by running the command below
`
root@haproxy-01:# haproxy -v
HA-Proxy version 1.8.8-1ubuntu0.4 2019/01/24
Copyright 2000-2018 Willy Tarreau <willy@haproxy.org>`
- Go to /etc/haproxy/haproxy.cfg and replace its content with the snippet below
`
global
daemon
maxconn 256
defaults
mode tcp
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend http
bind :8080
default_backend stats
backend stats
mode http
stats enable
stats enable
stats uri /
stats refresh 1s
stats show-legends
stats admin if TRUE
frontend redis-read
bind *:6379
default_backend redis-online
frontend redis-write
bind *:6380
default_backend redis-primary
backend redis-primary
mode tcp
balance first
option tcp-check
tcp-check send info\ replication\r\n
tcp-check expect string role:master
server redis-01:192.168.1.11:6379 192.168.1.11:6379 maxconn 1024 check inter 1s
server redis-02:192.168.1.12:6379 192.168.1.12:6379 maxconn 1024 check inter 1s
server redis-03:192.168.1.13:6379 192.168.1.13:6379 maxconn 1024 check inter 1s
backend redis-online
mode tcp
balance roundrobin
option tcp-check
tcp-check send PING\r\n
tcp-check expect string +PONG
server redis-01:192.168.1.11:6379 192.168.1.11:6379 maxconn 1024 check inter 1s
server redis-02:192.168.1.12:6379 192.168.1.12:6379 maxconn 1024 check inter 1s
server redis-03:192.168.1.13:6379 192.168.1.13:6379 maxconn 1024 check inter 1s`
- Restart the HAProxy service
`
sudo systemctl restart haproxy`
- You can browse the Stats UI that comes out of the box with HAProxy by visiting http://
:8080 on Your browser
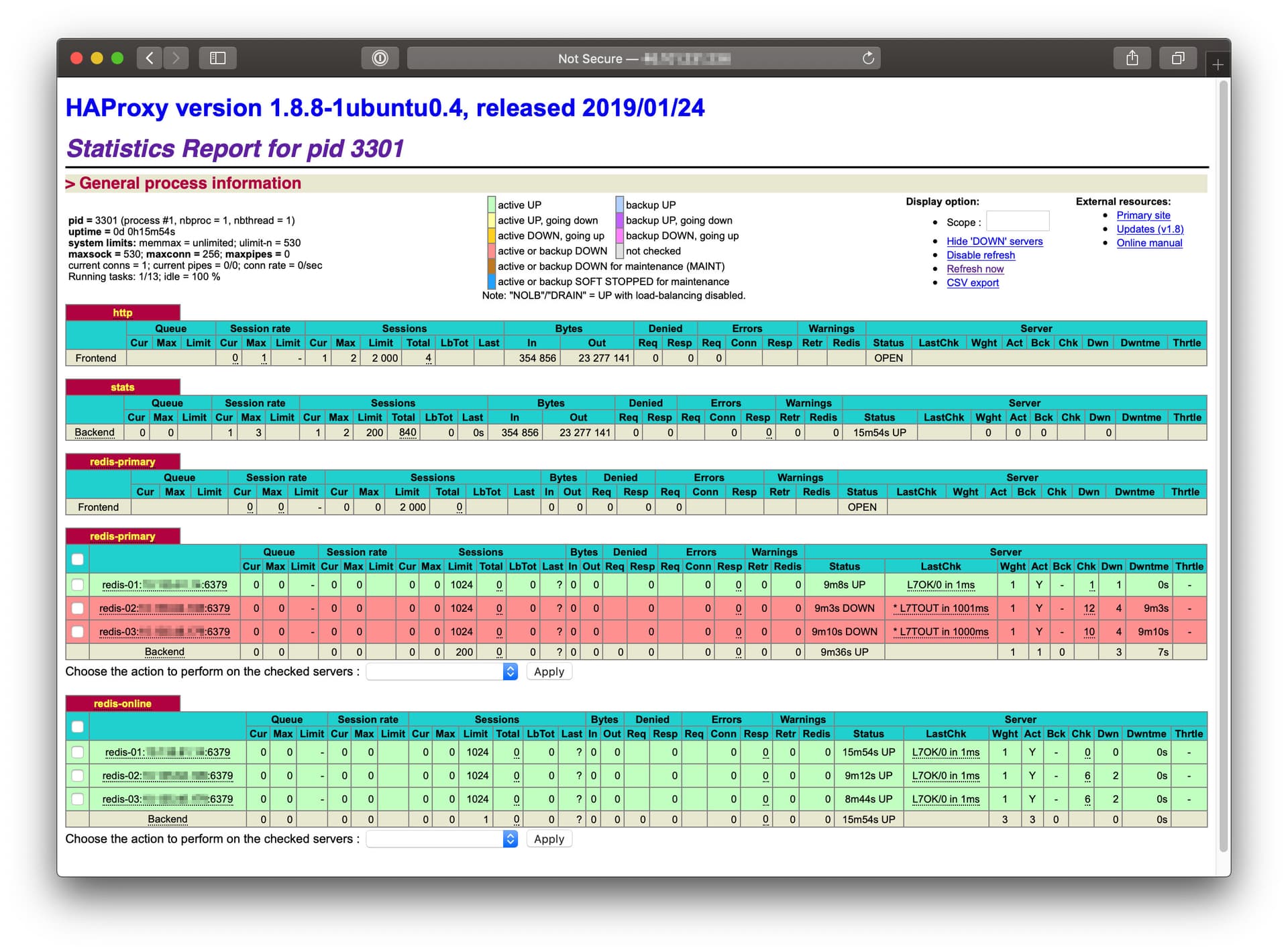
TIP: You can access the interface without exposing port 8080 on the VM by tunneling via SSH with
ssh -N -L 8080:localhost:8080 <YOUR_USER>@<YOUR_IP_OR_DOMAIN>and then visitlocalhost:8080from a browser on the machine You are sitting on.
- Check that Your HAProxy server is routing traffic to Your primary Redis node by executing the command below on Your HAProxy VM.
`
apt install redis-tools -y
redis-cli -h 192.168.1.10 -p 6379 info replication | grep role
role:master
redis-cli -h 192.168.1.10 -p 6379 info replication | grep role
role:slave
redis-cli -h 192.168.1.10 -p 6379 info replication | grep role
role:slave
redis-cli -h 192.168.1.10 -p 6379 info replication | grep role
role:master
redis-cli -h 192.168.1.10 -p 6379 info replication | grep role
role:slave
redis-cli -h 192.168.1.10 -p 6379 info replication | grep role
role:slave`
As You can see above the roundrobin balance algorithm sends each request to all the machines listed under the backend redis-online section in our haproxy.cfg
Now check the 6380 port which is designated for write requests.
It should return something similar to the response below. The important part is role:master as Your HAProxy should always route traffic to the master VM at any given time.
`
redis-cli -h <YOUR_HAPROXY_PRIVATE_IP> -p 6380 info replication``
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.1.12,port=6379,state=online,offset=300869,lag=0
slave1:ip=192.168.1.13,port=6379,state=online,offset=300869,lag=1
master_replid:5727c2e7a8807e43cde4171209059c497965626f
master_replid2:4b9ba6abc844fd849ee067ccf4bc1d1aefe3cade
master_repl_offset:301301
second_repl_offset:65678
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:454
repl_backlog_histlen:30084``
That's it, You should now have everything You need to setup a well functioning Redis cluster.
Shell Scripting
Shell scripting is a scripting language that runs on top of a shell environment which is used to perform automation for repetitive tasks, manage system configurations, and execute a series of commands by writing it in a script and running it. Some of the requirements where shell script will help us is system administration, software installations, file manipulations, etc.
The basic syntax of Shell Script is below and the filename ends with .sh file extension.
#!/bin/bashvariable declaration / series of commands / functions / functions calls etc
Shebang
The first line of a shell script is always a shebang usually the bash #!/bin/bash which specifies the interpreter to execute the script. When the script is executed the kernel reads the shebang line and uses that interpreter to execute that script.
-
cat $SHELL- displays the current shell type you are working on. -
cat /etc/shells- displays the available shells of that machine.
echo "The first line in this script above is the 'shebang'"
Note: Basically,
#!/bin/bashis the superset of#!/bin/sh(shell) so in your scripts always incorporate the use of the bash shebang as it is universally used and I have used the same to explain the syntaxes.
Steps to run a Shell Script
To run a shell script we need to follow the below two steps:
-
make the script executable by giving execute permission
chmod u+x <scriptFile> -
./<fileName>to run the shell script from the terminal.
Now let's learn the concepts available in Shell Scripting. Boom!!
Reading Input from User
The read command helps in reading the user input (i.e. line of text) from the standard input stdin.
#!/bin/bash
# reads input from the user and puts it in the username variable\
echo "Enter Username: "\
read username\
echo $usernamedisplays the prompt message\
-p stand for prompt\
reads input from the user and puts it in the newusername variable\
read -p "Enter the new username: " newusername\
echo $newusernamereads input from the user & hides the text from echoing in the terminal\
-s stands for silent\
read -sp "Enter Password: " password\
echo ""\
echo $passwordif you don't wish to specify the variable name for the read we can use $REPLY to echo the value
#!/bin/bash
echo "Enter the username: "\
read\
echo "Read without variable name assignment: "$REPLYCommand Substitution
Command substitution enables the output of the command to be substituted as a value to the variable. It can be done in two ways:
-
Using backticks (`)
-
Using the dollar sign ($)
#!/bin/bash echo "Method 1 - using backticks"\ working_dir=`pwd`\ echo $working_dir echo "Method 2 - using $ sign"\ working_dir=$(pwd)\ echo $working_dir
Argument Passing
We can pass arguments that can be used inside the scripts when it is executed. Those arguments can be accessed by the script using special variables like $1 $2 $3 etc.
-
$0- returns the file name of the shell script. -
$@- returns all arguments passed from cli. -
$#- returns the no of arguments passed from cli.
Let's say we have a script file named argument_passing.sh and let's pass 2 arguments to it.
argument_passing.sh "PV" "DevOps Engineer"
#!/bin/bash
# gives the filename of the script itself\
echo "FileName Argument: "$0 # argument_passing.sh
# gives the first argument passed\
echo "First Argument: "$1 # Vish
# gives the second argument passed\
echo "Second Argument: "$2 # DevOps Engineer
# displays all arguments passed\
echo "All Arguments: "$@ # Vish DevOps Engineer
# displays number of arguments passed\
echo "No of Arguments: "$# # 2Arithmetic Operations
In shell scripting, to perform arithmetic operations we need to use double parenthesis (( )) which is used for arithmetic expansion on integers. The double parenthesis (( )) is also called a unary operator.
#!/bin/bash
n1=10\
n2=5
echo "Sum of two numbers: "$(($n1+$n2)) # Addition\
echo "Sub of two numbers: "$(($n1-$n2)) # Substraction\
echo "Mul of two numbers: "$(($n1*$n2)) # Mulitplication\
echo "Div of two numbers: "$(($n1/$n2)) # Division\
echo "Modulus of two numbers: "$(($n1%$n2)) Modulus
We can also use test command to work with arithmetic and string operations which provide more flexibility along with unary operators.
Conditionals
In shell scripting, [[ ]] or test command can be used for evaluating conditional expressions. Below are certain unary operators that can be used for testing the conditions
Conditions
-
[[ -z STRING ]]- Empty string -
[[ -n STRING ]]- Not empty string -
[[ STRING == STRING ]]- Equal -
[[ STRING != STRING ]]- Not equal -
[[ NUM -eq NUM ]]- Equal -
[[ NUM -ne NUM ]]- Not equal -
[[ NUM -lt NUM ]]- Less than -
[[ NUM -le NUM ]]- Less than or equal -
[[ NUM -gt NUM ]]- Greater than -
[[ NUM -ge NUM ]]- Greater than or equal -
[[ ! EXPR ]]- Not -
[[ X && Y ]]- And -
[[ X || Y ]]- Or
File Conditions
-
[[ -e FILE ]]- Exists -
[[ -r FILE ]]- Readable -
[[ -h FILE ]]- Symbolic link -
[[ -d FILE ]]- Directory -
[[ -w FILE ]]- Writable file -
[[ -s FILE ]]- File size is > 0 bytes -
[[ -f FILE ]]- File -
[[ -x FILE ]]- Executable file#!/bin/bash a=10\ b=20 # less than using square brackets\ if [[ $a -lt $b ]]\ then\ echo "a is less than b"\ else\ echo "a is not less than b"\ fi
less than using test command\
if test "$a" -lt "$b"\
then\
echo "a is less than b"\
else\
echo "a is not less than b"\
fiLoops
if else
if else loop is a conditional statement that allows executing different commands based on the condition true/false. Here square brackets [[ ]] are used to evaluate a condition.
Let's create a file named ifelse.sh and input the below code
#!/bin/bash
# -e stands for exists\
if [[ -e ./ifelse.sh ]]\
then\
echo "File exists"\
else\
echo "File does not exist"\
fi elif
elif is a combination of both else and if. It is used to create multiple conditional statements and it must be always used in conjunction with if else statement
#!/bin/bash
read -p "Enter the number between 1 to 3: " number
if [[ $number -eq 1 ]]\
then\
echo "The number entered is 1"\
elif [[ $number -eq 2 ]]\
then\
echo "The number entered is 2"\
elif [[ $number -eq 3 ]]\
then\
echo "The number entered is 3"\
else\
echo "Invalid Number"\
fifor
The for loop is used to iterate over a sequence of values and below is the syntax
#!/bin/bash
for i in {1..10}\
do\
echo "Val: $i"\
doneC style/Old Style of for loop\
for((i=0;i<=10;i++))\
do\
echo "Val: $i"\
donewhile
The while loop is used to execute a set of commands repeatedly as long as a certain condition is true. The loop continues until the condition is false.
#!/bin/bash
count=0
while [ $count -lt 5 ]\
do\
echo $count\
count=$(($count+1))\
doneuntil
The until loop in shell scripting is used to execute a block of code repeatedly until a certain condition is met.
#!/bin/bash
count=1
until [ $count -gt 5 ]\
do\
echo $count\
count=$(($count+1))\
doneArrays
An array is a variable that can hold multiple values under a single name
-
${arrayVarName[@]}- displays all the values of the array. -
${#arrayVarName[@]}- displays the lenght of the array. -
${arrayVarName[1]}- displays the first element of the array -
${arrayVarName[-1]}- displays the last element of the array -
unset arrayVarName[2]- deletes the 2 element#!/bin/bash # Declare an array of fruits\ fruits=("apple" "banana" "orange" "guava") # Print the entire array\ echo "All fruits using @ symbol: ${fruits[@]}"\ echo "All fruits using * symbol: ${fruits[*]}" # Print the third element of the array\ echo "Third fruit: ${fruits[2]}" # Print the length of the array\ echo "Number of fruits: ${#fruits[@]}"
Break Statement
break is a keyword. It is a control statement that is used to exit out of a loop ( for, while, or until) when a certain condition is met. It means that the control of the program is transferred outside the loop and resumes with the next set of lines in the script
#!/bin/bash
count=1
while true\
do\
echo "Count is $count"\
count=$(($count+1))\
if [ $count -gt 5 ]; then\
echo "Break statement reached"\
break\
fi\
doneContinue statement
continue is a keyword that is used inside loops (such as for, while, and until) to skip the current iteration of the loop and move on to the next iteration. It means that when the continue keyword is encountered while executing a loop the next set of lines in that loop will not be executed and moves to the next iteration.
#!/bin/bash
for i in {1..10}\
do\
if [ $i -eq 5 ]\
then\
continue\
fi\
echo $i\
doneFunctions
Functions are a block of code which can be used again and again for doing a specific task thus providing code reusability.
Normal Function
#!/bin/bash
sum(){\
echo "The numbers are: $n1 $n2"\
sum_val=$(($n1+$n2))\
echo "Sum: $sum_val"\
}
n1=$1\
n2=$2\
sumFunction with return values
To access the return value of the function we need to use $? to access that value
#!/bin/bash
sum(){\
echo "The numbers are: $n1 $n2"\
sum_val=$(($n1+$n2))\
echo "Sum: $sum_val"\
return $sum_val\
}
n1=$1\
n2=$2\
sum
echo "Retuned value from function is $?"Variables
The variable is a placeholder for saving a value which can be later accessed using that name. There are two types of variable
-
Global- Variable defined outside a function which can be accessed throughout the script -
Local- Variable defined inside a function and can be accessed only within it
!/bin/bash
x & y are global variables\
x=10\
y=20
sum(){\
sum=$(($x+$y))\
echo "Global Variable Addition: $sum"\
}
sum
sub(){\
# a & b are local variables\
a=20\
b=10\
sub=$(($a-$b))\
echo "Local Variable Substraction: $sub"\
}
subDictionaries
In shell scripting, dictionaries are implemented using associative arrays. An associative array is an array that uses a string as an index instead of an integer
#!/bin/bash
# declare a associative array\
declare -A colours
# add key value pairs\
colours['apple']=red\
colours['banana']=yellow\
colours['orange']=orange\
colours['guava']=green\
colours['cherry']=red
echo "Size of dict: ${#colours[@]}"\
echo "Color of apple: ${colours['apple']}"\
echo "All dict keys: ${!colours[@]}"\
echo "All dict values: ${colours[@]}"
# Delete cherry key\
unset colours['cherry']\
echo "New dict: ${colours[@]}"
# iterate over keys\
for key in ${!colours[@]}\
do\
echo $key\
done
# iterate over values\
for value in ${colours[@]}\
do\
echo $value\
doneSet Options
The set command allows us to change or display the values of shell options. We can use it to set options to turn certain shell options on & off.
set -x - it's like a debug mode. whatever commands are being performed will be printed first then the output of the command will be displayed
set -e - immediately exits the script when a non zero exit code is occurred. But when we have commands with pipe say sdfdsf | echo 'vish'. Here since the last command executed in the line is echo which returns zero exit code so the entire line of command is considered success but the previous command sdsds will return non zero which is wrong. To catch this we can use the below set option
set -o pipefail - To overcome the above pipe command error we can use set -o pipefail option which will catch and stop the script immediately. So here each command should return a zero exit code. If not the script will fail.
So that's it about Shell scripting. With the above basic syntaxes understanding now we are in a position to develop complex shell scripts. Hope I was able to make a good understanding of the concept. Thank you.
You can refer to all the shell script files in my GitHub repo: https://github.com/devopsvish/shell-scripting
title: "5 Reasons YOU need to upgrade to MySQL 8.0" author: "PV" date: "2023-10-24"
5 Reasons YOU need to upgrade to MySQL 8.0
As you may know, MySQL 5.7 will reach End of Life (EOL) in October 21, 2023.
That means there will be no new updates, and more importantly, no new security fixes for discovered vulnerabilities.
EOL alone should be enough of a reason to upgrade to MySQL 8.0, but if you are still hesitant, here are five more reason to consider the upgrade.
-
Resiliency: built-in HA mechanism
MySQL introduced the first implementation of Group Replication in version 5.7, but it was only in MySQL 8.0 where it has become a mature and reliable feature. The Group Replication is now considered a solid solution addressing HA and resiliency needs.
-
Performance and Scalability
The dictionaries in MySQL were refactored, making them transactional and with
improved locking mechanisms. This has resulted in higher performance as well as the
ability to easily roll back operations in a safe and performant way. These scalability
improvements are designed to work out of the box, provided you are using the
InnoDB engine.
-
Security
The static privileges in 5.7 were expanded with dynamic privileges. Roles were added, making it possible to group permissions and then assign roles to users. This is helpful in larger organizations where users are typically representing groups, or, more importantly, where managing all the individuals could be a tedious and error-prone task.
-
MySQL 8.0 is secure and stabilized
If early cautionary tales have you hesitant about upgrading from 5.7 to 8.0, realize that most of them were unfounded and that others have been addressed. Yes, early versions of MySQL
8.0 caused some problems, but since then, numerous fixes and improvements have been implemented.
-
Tons of new improvements!
You want more? On top of these high-visibility topics, MySQL 8.0 also comes with a collection of smaller
yet valuable improvements that support the ease of use, flexibility and performance.
These include:
-
The default character set of UTF8MB4 gives Unicode version 9.0 support —
meaning you get Umlauts, Cedils, and C-J-K Language support in your data,
plus emojis. MySQL 8.0 is optimized around this character set, giving you all the international characters you need to support global operations
The Structured Query Language has been greatly enhanced. If you have trouble writing subqueries, you can rejoice in lateral-derived joins and Common Table Expressions (CTEs). There is a new intersect clause to aid with sets. -
EXPLAIN ANALYZE is a big boon to query tuning. EXPLAIN without the ANALYZE gives you the server’s estimated analysis of the performance of your query. Adding ANALYZE causes the query to execute and the numbers returned to report the real numbers of
the query’s performance. Add in INVISIBLE INDEXes, and you can test the efficiency of an index without risking a disastrous rebuild after a delete.
Ready to upgrade? Check out: MySQL 5.7 to MySQL 8.0 Upgrade Prep
title: "5 Reasons YOU need to upgrade to MySQL 8.0" author: "PV" date: "2023-10-24"
MySQL 5.7 to MySQL 8.0 Upgrade Prep
Preparing Your Installation for Upgrade
Before upgrading to the latest MySQL 8.0 release, ensure the upgrade readiness of your current MySQL 5.7 or MySQL 8.0 server instance by performing the preliminary checks described below. The upgrade process may fail otherwise.
Tip
Consider using the MySQL Shell upgrade checker utility that enables you to verify whether MySQL server instances are ready for upgrade. You can select a target MySQL Server release to which you plan to upgrade, ranging from the MySQL Server 8.0.11 up to the MySQL Server release number that matches the current MySQL Shell release number. The upgrade checker utility carries out the automated checks that are relevant for the specified target release, and advises you of further relevant checks that you should make manually. The upgrade checker works for all GA releases of MySQL 5.7, 8.0, and 8.1. Installation instructions for MySQL Shell can be found here.
Preliminary checks:
-
The following issues must not be present:
-
There must be no tables that use obsolete data types or functions.
In-place upgrade to MySQL 8.0 is not supported if tables contain old temporal columns in pre-5.6.4 format (
TIME,DATETIME, andTIMESTAMPcolumns without support for fractional seconds precision). If your tables still use the old temporal column format, upgrade them usingREPAIR TABLEbefore attempting an in-place upgrade to MySQL 8.0. For more information, see Server Changes, in MySQL 5.7 Reference Manual. -
There must be no orphan
.frmfiles. -
Triggers must not have a missing or empty definer or an invalid creation context (indicated by the
character_set_client,collation_connection,Database Collationattributes displayed bySHOW TRIGGERSor theINFORMATION_SCHEMATRIGGERStable). Any such triggers must be dumped and restored to fix the issue.
To check for these issues, execute this command:
mysqlcheck -u root -p --all-databases --check-upgradeIf mysqlcheck reports any errors, correct the issues.
-
-
There must be no partitioned tables that use a storage engine that does not have native partitioning support. To identify such tables, execute this query:
SELECT TABLE_SCHEMA, TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE ENGINE NOT IN ('innodb', 'ndbcluster') AND CREATE_OPTIONS LIKE '%partitioned%';Any table reported by the query must be altered to use
InnoDBor be made nonpartitioned. To change a table storage engine toInnoDB, execute this statement:ALTER TABLE table_name ENGINE = INNODB;For information about converting
MyISAMtables toInnoDB, see Section 15.6.1.5, "Converting Tables from MyISAM to InnoDB".To make a partitioned table nonpartitioned, execute this statement:
ALTER TABLE table_name REMOVE PARTITIONING; -
Some keywords may be reserved in MySQL 8.0 that were not reserved previously. See Section 9.3, "Keywords and Reserved Words". This can cause words previously used as identifiers to become illegal. To fix affected statements, use identifier quoting. See Section 9.2, "Schema Object Names".
-
There must be no tables in the MySQL 5.7
mysqlsystem database that have the same name as a table used by the MySQL 8.0 data dictionary. To identify tables with those names, execute this query:SELECT TABLE_SCHEMA, TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE LOWER(TABLE_SCHEMA) = 'mysql' and LOWER(TABLE_NAME) IN ( 'catalogs', 'character_sets', 'check_constraints', 'collations', 'column_statistics', 'column_type_elements', 'columns', 'dd_properties', 'events', 'foreign_key_column_usage', 'foreign_keys', 'index_column_usage', 'index_partitions', 'index_stats', 'indexes', 'parameter_type_elements', 'parameters', 'resource_groups', 'routines', 'schemata', 'st_spatial_reference_systems', 'table_partition_values', 'table_partitions', 'table_stats', 'tables', 'tablespace_files', 'tablespaces', 'triggers', 'view_routine_usage', 'view_table_usage' );Any tables reported by the query must be dropped or renamed (use
RENAME TABLE). This may also entail changes to applications that use the affected tables. -
There must be no tables that have foreign key constraint names longer than 64 characters. Use this query to identify tables with constraint names that are too long:
SELECT TABLE_SCHEMA, TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME IN (SELECT LEFT(SUBSTR(ID,INSTR(ID,'/')+1), INSTR(SUBSTR(ID,INSTR(ID,'/')+1),'_ibfk_')-1) FROM INFORMATION_SCHEMA.INNODB_SYS_FOREIGN WHERE LENGTH(SUBSTR(ID,INSTR(ID,'/')+1))>64);For a table with a constraint name that exceeds 64 characters, drop the constraint and add it back with constraint name that does not exceed 64 characters (use
ALTER TABLE). -
There must be no obsolete SQL modes defined by
sql_modesystem variable. Attempting to use an obsolete SQL mode prevents MySQL 8.0 from starting. Applications that use obsolete SQL modes should be revised to avoid them. For information about SQL modes removed in MySQL 8.0, see Server Changes. -
There must be no views with explicitly defined columns names that exceed 64 characters (views with column names up to 255 characters were permitted in MySQL 5.7). To avoid upgrade errors, such views should be altered before upgrading. Currently, the only method of identify views with column names that exceed 64 characters is to inspect the view definition using
SHOW CREATE VIEW. You can also inspect view definitions by querying the Information SchemaVIEWStable. -
There must be no tables or stored procedures with individual
ENUMorSETcolumn elements that exceed 255 characters or 1020 bytes in length. Prior to MySQL 8.0, the maximum combined length ofENUMorSETcolumn elements was 64K. In MySQL 8.0, the maximum character length of an individualENUMorSETcolumn element is 255 characters, and the maximum byte length is 1020 bytes. (The 1020 byte limit supports multibyte character sets). Before upgrading to MySQL 8.0, modify anyENUMorSETcolumn elements that exceed the new limits. Failing to do so causes the upgrade to fail with an error. -
Before upgrading to MySQL 8.0.13 or higher, there must be no table partitions that reside in shared
InnoDBtablespaces, which include the system tablespace and general tablespaces. Identify table partitions in shared tablespaces by queryingINFORMATION_SCHEMA:If upgrading from MySQL 5.7, run this query:
SELECT DISTINCT NAME, SPACE, SPACE_TYPE FROM INFORMATION_SCHEMA.INNODB_SYS_TABLES WHERE NAME LIKE '%#P#%' AND SPACE_TYPE NOT LIKE 'Single';If upgrading from an earlier MySQL 8.0 release, run this query:
SELECT DISTINCT NAME, SPACE, SPACE_TYPE FROM INFORMATION_SCHEMA.INNODB_TABLES WHERE NAME LIKE '%#P#%' AND SPACE_TYPE NOT LIKE 'Single';Move table partitions from shared tablespaces to file-per-table tablespaces using
ALTER TABLE ... REORGANIZE PARTITION:ALTER TABLE table_name REORGANIZE PARTITION partition_name INTO (partition_definition TABLESPACE=innodb_file_per_table); -
There must be no queries and stored program definitions from MySQL 8.0.12 or lower that use
ASCorDESCqualifiers forGROUP BYclauses. Otherwise, upgrading to MySQL 8.0.13 or higher may fail, as may replicating to MySQL 8.0.13 or higher replica servers. For additional details, see SQL Changes. -
Your MySQL 5.7 installation must not use features that are not supported by MySQL 8.0. Any changes here are necessarily installation specific, but the following example illustrates the kind of thing to look for:
Some server startup options and system variables have been removed in MySQL 8.0. See Features Removed in MySQL 8.0, and Section 1.4, "Server and Status Variables and Options Added, Deprecated, or Removed in MySQL 8.0". If you use any of these, an upgrade requires configuration changes.
Example: Because the data dictionary provides information about database objects, the server no longer checks directory names in the data directory to find databases. Consequently, the
--ignore-db-diroption is extraneous and has been removed. To handle this, remove any instances of--ignore-db-dirfrom your startup configuration. In addition, remove or move the named data directory subdirectories before upgrading to MySQL 8.0. (Alternatively, let the 8.0 server add those directories to the data dictionary as databases, then remove each of those databases usingDROP DATABASE.) -
If you intend to change the
lower_case_table_namessetting to 1 at upgrade time, ensure that schema and table names are lowercase before upgrading. Otherwise, a failure could occur due to a schema or table name lettercase mismatch. You can use the following queries to check for schema and table names containing uppercase characters:mysql> select TABLE_NAME, if(sha(TABLE_NAME) !=sha(lower(TABLE_NAME)),'Yes','No') as UpperCase from information_schema.tables;As of MySQL 8.0.19, if
lower_case_table_names=1, table and schema names are checked by the upgrade process to ensure that all characters are lowercase. If table or schema names are found to contain uppercase characters, the upgrade process fails with an error.Note
Changing the
lower_case_table_namessetting at upgrade time is not recommended.
If upgrade to MySQL 8.0 fails due to any of the issues outlined above, the server reverts all changes to the data directory. In this case, remove all redo log files and restart the MySQL 5.7 server on the existing data directory to address the errors. The redo log files (ib_logfile*) reside in the MySQL data directory by default. After the errors are fixed, perform a slow shutdown (by setting innodb_fast_shutdown=0) before attempting the upgrade again.
title: "NEW Website re-design!" author: "PV" date: "2023-10-20"
High-Availability MySQL cluster with load balancing using HAProxy and Heartbeat
We will be building a high available MySQL database cluster, from two master MySQL nodes, with load balancing and failover capability based on HAProxy & Heartbeat.
On most of modern projects, the database availability is critical component. A possible solution would be creating a distributed database cluster, from more then one MySQL server, that can take care of load balancing, failover capabilities and data replication. Also, you can split incoming requests and load balance high load.
In this example, I will show creating a MySQL cluster from two master nodes, main idea is to create a pair of servers with same configurations and one virtual IP for taking requests. This cluster will continue working even after totally losing one of the nodes.
We’ll use a two servers (virtual or bare metal) with pair of MySQL masters and a pair of HAProxy installed on them, the main virtual IP will be configured with Heartbeat. Please mind that in this example only one HAProxy be using in one time period, the second HAProxy will be standing in hot reserve. MySQL servers will be recycle with round robin type of load balancing.
The schema with two servers was chosen for making an example simpler. Of course if you have an additional servers, you can create a more complicated configurations, putting HAProxy with Heartbeat in external LB cluster and so on. But anyway, this example will be a quite enough for building a strong looking DB cluster inside your project.
-
Preparing.
First we’ll need to choose few subnets for the MySQL replications and for the HAProxy with Heartbeat, better separate them and if your server have a few network interface put these subnets on different interfaces as well.192.168.0.0/24 - network for DB traffic
192.168.0.1 IP for MySQL1, 192.168.0.2 IP for MySQL2.
10.10.10.0/24 - network for the Heartbeat & HAProxy.
10.10.10.1 Virtual IP for taking requests, 10.10.10.2 main IP for sever1, 10.10.10.3 main IP for server2.
The /29 subnets will be quite enough in fact :)
-
Configuring MySQL servers with master - master replication.
First we need to install MySQL on both of ours servers:apt-get update && apt-get upgrade -y
apt-get install mysql-server mysql-client
Then edit the /etc/mysql/my.cnf on first and second node, to enable replication between MySQL servers and make them use IPS from 192.168.0.0/24 subnet:
Server1 configuration.
[mysqld]
bind-address = 192.168.0.1
server_id = 1
log_bin = /var/log/mysql/mysql-bin.log
log_bin_index = /var/log/mysql/mysql-bin.log.index
relay_log = /var/log/mysql/mysql-relay-bin
relay_log_index = /var/log/mysql/mysql-relay-bin.index
expire_logs_days = 10
max_binlog_size = 100M
log_slave_updates = 1
auto-increment-increment = 2
auto-increment-offset = 1
Server2 configuration.
[mysqld]
bind-address = 192.168.0.2
server_id = 2
log_bin = /var/log/mysql/mysql-bin.log
log_bin_index = /var/log/mysql/mysql-bin.log.index
relay_log = /var/log/mysql/mysql-relay-bin
relay_log_index = /var/log/mysql/mysql-relay-bin.index
expire_logs_days = 10
max_binlog_size = 100M
log_slave_updates = 1
auto-increment-increment = 2
auto-increment-offset = 2Then restart them both and make sure MySQL leaf on specified IP:
server1# systemctl restart mysql
server1# netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 192.168.0.1:3306 0.0.0.0:* LISTEN 9057/mysqld
server2# systemctl restart mysql
server2# netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 192.168.0.2:3306 0.0.0.0:* LISTEN 8740/mysqldNow will create a user for replication between databases, you can use pwgen utility to generate strong enough password. Connect to each MySQL servers and create this user with IP from opposite server:
server1# mysql -u root -p
MariaDB> GRANT REPLICATION SLAVE ON *.* TO 'replicauser'@'192.168.0.2' IDENTIFIED BY 'somestrongpassword';
server2# mysql -u root -p
MariaDB> GRANT REPLICATION SLAVE ON *.* TO 'replicauser'@'192.168.0.1' IDENTIFIED BY 'somestrongpassword';Check that replicauser have access for each MySQL server.
server1# mysql -u replicauser -p -h 192.168.0.2
Enter password: somestrongpassword
Welcome to the MariaDB monitor. Commands end with ; or \g.bla bla...
server2# mysql -u replicauser -p -h 192.168.0.1
Enter password: somestrongpassword
Welcome to the MariaDB monitor. Commands end with ; or \g.bla bla...
Fine, now we can continue with configuring replication between MySQL servers. From that time better to have opened two consoles from both of MySQL servers, as we need to input commands, based on output from another server.
Get the MySQL master status on server1:
server1# mysql -u root -p
MariaDB> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000002 | 531 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)We’ll need the File and Position information, from this output. Open the MySQL console on server2 and configure the slave relation with first server.
server2# mysql -u root -p
MariaDB> STOP SLAVE;
MariaDB> CHANGE MASTER TO master_host='192.168.0.1', master_port=3306, master_user='replicauser', master_password='somestrongpassword', master_log_file='mysql-bin.000002', master_log_pos=531;
MariaDB> START SLAVE;Now query the master status from server2 and configure slave relation for MySQL on first server.
server2# mysql -u root -p
MariaDB> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000002 | 531 | | |
+------------------+----------+--------------+------------------+
1 row in set (0.00 sec)
server1# mysql -u root -p
MariaDB> STOP SLAVE;
MariaDB> CHANGE MASTER TO master_host='192.168.0.2', master_port=3306, master_user='replicauser', master_password='somestrongpassword', master_log_file='mysql-bin.000002', master_log_pos=531;
MariaDB> START SLAVE;OK, if all was done right, we must have a working replication between MySQL masters. You can create some test DB and check this.
server1# mysql -u root -p
MariaDB> CREATE DATABASE TESTDB;
MariaDB> CREATE TABLE TESTDB.REPLICA (`id` varchar(40));Then check this database was appeared on second server as well:
server2# mysql -u root -p
MariaDB> SHOW TABLES IN TESTDB;
+------------------+
| Tables_in_TESTDB |
+------------------+
| REPLICA |
+------------------+
1 row in set (0.00 sec)And as you can see, the TESTDB base was successfully replicated to server2. We just completed a first stage of creating our failover cluster.
- Configuring HAProxy on both servers.
In second stage we’ll install and configure two absolutely identical HAProxy on both of our servers, for balancing a incoming requests between MySQL servers.
First we need to add additional user on our MySQL servers (user must be created without any password), this user will be used by HAProxy for checking a health status of MySQL servers.
server1# mysql -u root -p
MariaDB> CREATE USER 'haproxy_check'@'%';
MariaDB> FLUSH PRIVILEGES;You can create this user on any of our MySQL servers, as we have a replication configured between them. Check that user was added, using this command:
server1# mysql -u root -p -e "SELECT User, Host FROM mysql.user"
Enter password:
+---------------+-------------+
| User | Host |
+---------------+-------------+
| haproxy_check | % |
| replicauser | 192.168.0.2 |
| root | localhost |
+---------------+-------------+
server2# mysql -u root -p -e "SELECT User, Host FROM mysql.user"
Enter password:
+---------------+-------------+
| User | Host |
+---------------+-------------+
| haproxy_check | % |
| replicauser | 192.168.0.1 |
| root | localhost |
+---------------+-------------+Also let’s create a user with root privileges, for making some test requests later:
server1# mysql -u root -p
MariaDB> CREATE USER 'haproxy_root'@'%' IDENTIFIED BY 'password';
MariaDB> GRANT ALL PRIVILEGES ON *.* TO 'haproxy_root'@'%';Now it’s time for HAProxy installation:
server1# apt-get install haproxy
server2# apt-get install haproxySave original config and create new one:
server1# mv /etc/haproxy/haproxy.cfg{,.back}
server1# vi /etc/haproxy/haproxy.cfgNext add this configuration on both servers:
global
user haproxy
group haproxy
defaults
mode http
log global
retries 2
timeout connect 3000ms
timeout server 5000ms
timeout client 5000ms
listen stats
bind 10.10.10.1:9999
stats enable
stats hide-version
stats uri /stats
stats auth statadmin:statadminpass
listen mysql-cluster
bind 10.10.10.1:3306
mode tcp
option mysql-check user haproxy_check
balance roundrobin
server mysql-1 192.168.0.1:3306 check
server mysql-2 192.168.0.2:3306 checkAs you can see, both HAProxy services will use 10.10.10.1, shared IP address. This virtual IP will move on between servers, so we need to make some trick and enable net.ipv4.ip_nonlocal_bind sysctl option, to allow system services binding on the non-local IP.
Add to the file /etc/sysctl.conf this option:
server1# vi /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind=1
server2# vi /etc/sysctl.conf
net.ipv4.ip_nonlocal_bind=1Then run
sysctl -pAfter this, we can start HAProxy on both servers:
server1# systemctl start haproxy
server2# systemctl start haproxyCheck they started on shared IP 10.10.10.1:
server1# netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 192.168.0.1:3306 0.0.0.0:* LISTEN 918/mysqld
tcp 0 0 10.10.10.1:3306 0.0.0.0:* LISTEN 802/haproxy
tcp 0 0 10.10.10.1:9999 0.0.0.0:* LISTEN 802/haproxy
tcp 0 0 10.10.10.2:22 0.0.0.0:* LISTEN 785/sshd
server2# netstat -ntlp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 192.168.0.2:3306 0.0.0.0:* LISTEN 918/mysqld
tcp 0 0 10.10.10.1:3306 0.0.0.0:* LISTEN 802/haproxy
tcp 0 0 10.10.10.1:9999 0.0.0.0:* LISTEN 802/haproxy
tcp 0 0 10.10.10.3:22 0.0.0.0:* LISTEN 785/sshdEverything look’s OK, both servers was started using virtual IP, also we configured a stats page on 9999 port, so you can check the HAProxy status on http://10.10.10.1:9999/stats using statadmin:statadminpass.
- Configuring Heartbeat with shared IP.
On last stage we need to configure the Heartbeat service on both of the servers, and create shared IP, that will be used for serving incoming requests. This IP will migrate between servers if something wrong happens to one of them.
Install Heartbeat on both servers:
server1# apt-get install heartbeat
server1# systemctl enable heartbeat
server2# apt-get install heartbeat
server2# systemctl enable heartbeatNow we need to create a few configuration files for it, they will be mostly the same for the server1 and server2.
Create a /etc/ha.d/authkeys, in this file Heartbeat stored data to authenticate each other. File will be the same on both servers:
server1# vi /etc/ha.d/authkeys
auth 1
1 md5 securepass
server2# vi /etc/ha.d/authkeys
auth 1
1 md5 securepassChange the securepass to your strong secure password. Also, this file need to be owned by root only, so:
server1# chmod 600 /etc/ha.d/authkeys
server2# chmod 600 /etc/ha.d/authkeysNext will create a main configuration for Heartbeat on both servers, it’ll be a bit different for server1 and server2, create /etc/ha.d/ha.cf:
server1
server1# vi /etc/ha.d/ha.cf
# keepalive: how many seconds between heartbeats
#
keepalive 2
#
# deadtime: seconds-to-declare-host-dead
#
deadtime 10
#
# What UDP port to use for udp or ppp-udp communication?
#
udpport 694
bcast ens18
mcast ens18 225.0.0.1 694 1 0
ucast ens18 10.10.10.3
# What interfaces to heartbeat over?
udp ens18
#
# Facility to use for syslog()/logger (alternative to log/debugfile)
#
logfacility local0
#
# Tell what machines are in the cluster
# node nodename ... -- must match uname -n
node server1
node server2
server2
server1# vi /etc/ha.d/ha.cf
# keepalive: how many seconds between heartbeats
#
keepalive 2
#
# deadtime: seconds-to-declare-host-dead
#
deadtime 10
#
# What UDP port to use for udp or ppp-udp communication?
#
udpport 694
bcast ens18
mcast ens18 225.0.0.1 694 1 0
ucast ens18 10.10.10.2
# What interfaces to heartbeat over?
udp ens18
#
# Facility to use for syslog()/logger (alternative to log/debugfile)
#
logfacility local0
#
# Tell what machines are in the cluster
# node nodename ... -- must match uname -n
node server1
node server2The node names for this config you can get by running uname -n on your servers.
And last we need to create the /etc/ha.d/haresources file on server1 and server2. File be the same and in this file we’ll declare our shared IP address and master node by default:
server1# vi /etc/ha.d/haresources
server1 10.10.10.1
server2# vi /etc/ha.d/haresources
server1 10.10.10.1After all let’s start our Heartbeat services on both servers, and you must see that on server1 we have the virtual IP up:
server1# ip a 2: ens19: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether bla:bla:bla:bla brd ff:ff:ff:ff:ff:ff
inet 192.168.0.1/24 brd 192.168.0.255 scope global ens19
valid_lft forever preferred_lft forever
inet6 fe80::bla:bla:bla:bla/64 scope link
valid_lft forever preferred_lft forever
3: ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether bla:bla:bla:bla:bla:bla brd ff:ff:ff:ff:ff:ff
inet 10.10.10.2/24 brd 10.10.10.255 scope global ens18
valid_lft forever preferred_lft forever
inet 10.10.10.1/24 brd 10.10.10.255 scope global secondaryOK, now we have virtual IP assigned on our server1 and HAProxy listening on it, so we can check how it works, making test requests. From some external server run this commands:
# mysql -h 10.10.10.1 -u haproxy_root -p -e "show variables like 'server_id'"
Enter password:
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 1 |
+---------------+-------+
# mysql -h 10.10.10.1 -u haproxy_root -p -e "show variables like 'server_id'"
Enter password:
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 2 |
+---------------+-------+All working fine, you can see the “round robin” balancing between our MySQL servers. Now we need to check the failover when the server1 will go offline for example. Go and restart or shutdown the server1, and check that virtual IP was moved to server2 and requests to the MySQL servers still OK, but now there is only MySQL on server2 will respond:
server2# ip a 2: ens19: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether bla:bla:bla:bla brd ff:ff:ff:ff:ff:ff
inet 192.168.0.2/24 brd 192.168.0.255 scope global ens19
valid_lft forever preferred_lft forever
inet6 fe80::bla:bla:bla:bla/64 scope link
valid_lft forever preferred_lft forever
3: ens18: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether bla:bla:bla:bla:bla:bla brd ff:ff:ff:ff:ff:ff
inet 10.10.10.3/24 brd 10.10.10.255 scope global ens18
valid_lft forever preferred_lft forever
inet 10.10.10.1/24 brd 10.10.10.255 scope global secondaryCheck MySQL requests again:
# mysql -h 10.10.10.1 -u haproxy_root -p -e "show variables like 'server_id'"
Enter password:
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 2 |
+---------------+-------+
# mysql -h 10.10.10.1 -u haproxy_root -p -e "show variables like 'server_id'"
Enter password:
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 2 |
+---------------+-------+After the server1 will return online, the virtual IP will be moved back to it.
And we did, we just configured and tested our MySQL cluster, and it's now ready to serve requests.
title: "High-Availability MySQL cluster with load balancing using HAProxy and Heartbeat" author: "PV" date: "2023-10-18"
NEW Website re-design!
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vestibulum eget dignissim est. Duis et massa lacus. Curabitur a risus vel magna tincidunt commodo. Phasellus semper tempor risus, ut condimentum ex consectetur sit amet. Maecenas ullamcorper blandit tortor, in faucibus sem feugiat vitae. Mauris mollis ut lorem a aliquam. Integer eget nunc ullamcorper lorem porta eleifend. Aenean sit amet faucibus enim. Maecenas non cursus dui. Aenean blandit efficitur dui ut porta. Aenean non congue nulla.
title: "NEW Website re-design!" author: "PV" date: "2023-10-20"
Hello, World!
A "Hello, World!" program generally is a computer program that outputs or displays the message "Hello, World!". Such a program is very simple in most programming languages, and is often used to illustrate the basic syntax of a programming language. It is often the first program written by people learning to code.1 It can also be used as a sanity test to make sure that a computer language is correctly installed, and that the operator understands how to use it.
-
James A Langbridge (3 December 2013). Professional Embedded ARM Development. ISBN 9781118887820. ↩
How to generate this HTML file
Get portable-php to convert to HTML a collection of Markdown files.
- Write posts in
/content - Open
http://example.com/portable.phpin your browser - Save as
index.html
Or from the command-line:
php portable.php > index.htmlMarkdown examples
On top of plain Markdown, Markdown Extra adds support for footnotes, abbreviations, definition lists, tables, class and id attributes, fenced code blocks, and Markdown inside HTML blocks.
Additionally, images are properly enclosed in figure elements (with optional figcaption), and the loading="lazy" attribute is added.
This is bold, italic, this is an internal link, this is not code, press alt.


This is a level 2 heading
This is a level 3 heading
- This
- is
- a list
- This
- is
- an ordered list
This text is in a blockquote.
This is
preformatted
text.| This is a table | This column | This one is aligned right |
|---|---|---|
| This is a cell | is aligned | 1234.56 |
| This is a cell | center | 78.90 |
This sentence has a footnote.1
-
This is a footnote ↩
NEW Website re-design!
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vestibulum eget dignissim est. Duis et massa lacus. Curabitur a risus vel magna tincidunt commodo. Phasellus semper tempor risus, ut condimentum ex consectetur sit amet. Maecenas ullamcorper blandit tortor, in faucibus sem feugiat vitae. Mauris mollis ut lorem a aliquam. Integer eget nunc ullamcorper lorem porta eleifend. Aenean sit amet faucibus enim. Maecenas non cursus dui. Aenean blandit efficitur dui ut porta. Aenean non congue nulla.
title: "NEW Website re-design!" author: "PV" date: "2023-10-20"
Notes on the Fourth Dimension
by Jon Crabb
Men of broader intellect know that there is no sharp distinction betwixt the real and the unreal…
— H.P. Lovecraft, The Tomb (1917)
La Belle Époque, a beautiful term for a Beautiful Age, as Light and Understanding replace Fear and Superstition, and Science and Art join hands in unholy matrimony and set out to discover the world anew. Trains become underground worms burrowing through the city, displacing medieval graves in the name of modernity; the Aéro-Club de France sends men into the heavens, amazing the public; Muybridge proves horses fly too and wins a bet; Edison floods the world with light; biologists discover germs and defy Death; botanists grow tropical plants in Parisian glass-houses and affront Nature with hot-house orchids; the phonograph and the cinema fold Time and Space for the masses. And for some reason bicycles become rather popular. The world was getting smaller every day and the discoveries were getting bigger every week. How very diverting it all was…
In the land of Sona-Nyl there is neither time nor space, neither suffering nor death.
— H.P. Lovecraft, The White Ship (1920)
During the period we now call the fin de siècle, worlds collided. Ideas were being killed off as much as being born. And in a sort of Hegelian logic of thesis/antithesis/synthesis, the most interesting ones arose as the offspring of wildly different parents. In particular, the last gasp of Victorian spirituality infused cutting-edge science with a certain sense of old-school mysticism. Theosophy was all the rage; Huysmans dragged Satan into modern Paris; and eccentric poets and scholars met in the British Museum Reading Room under the aegis of the Golden Dawn for a cup of tea and a spot of demonology. As a result of all this, certain commonly-accepted scientific terms we use today came out of quite weird and wonderful ideas being developed at the turn of the century. Such is the case with space, which fascinated mathematicians, philosophers, and artists with its unfathomable possibilities.
Outside of sheltered mathematical circles, the trend began rather innocuously in 1884, when Edwin A. Abbott published the satirical novella Flatland: A Romance of Many Dimensions under the pseudonym A. Square. In the fine tradition of English satire, he creates an alternative world as a sort of nonsense arena to lampoon the social structures of Victorian England. In this two-dimensional world, different classes are made up of different polygons, and the laws concerning sides and angles that maintain that hierarchy are pushed to absurd proportions. Initially, the work was only moderately popular, but it introduced thought experiments on how to visualise higher dimensions to the general public. It also paved the ground for a much more esoteric thinker who would have much more far-reaching effects with his own mystical brand of higher mathematics.

In April 1904, C. H. Hinton published The Fourth Dimension, a popular maths book based on concepts he had been developing since 1880 that sought to establish an additional spatial dimension to the three we know and love. This was not understood to be time as we’re so used to thinking of the fourth dimension nowadays; that idea came a bit later. Hinton was talking about an actual spatial dimension, a new geometry, physically existing, and even possible to see and experience; something that linked us all together and would result in a “New Era of Thought”. (Interestingly, that very same month in a hotel room in Cairo, Aleister Crowley talked to Egyptian Gods and proclaimed a “New Aeon” for mankind. For those of us who amuse ourselves by charting the subcultural backstreets of history, it seems as though a strange synchronicity briefly connected a mystic mathematician and a mathematical mystic — which is quite pleasing.)
Hinton begins his book by briefly relating the history of higher dimensions and non-Euclidean maths up to that point. Surprisingly, for a history of mathematicians, it’s actually quite entertaining. Here is one tale he tells of János Bolyai, a Hungarian mathematician who contributed important early work on non-Euclidean geometry before joining the army:
It is related of him that he was challenged by thirteen officers of his garrison, a thing not unlikely to happen considering how differently he thought from everyone else. He fought them all in succession – making it his only condition that he should be allowed to play on his violin for an interval between meeting each opponent. He disarmed or wounded all his antagonists. It can be easily imagined that a temperament such as his was not one congenial to his military superiors. He was retired in 1833.
Mathematicians have definitely lost their flair. The notion of duelling with violinist mathematicians may seem absurd, but there was a growing unease about the apparently arbitrary nature of "reality" in light of new scientific discoveries. The discoverers appeared renegades. As the nineteenth century progressed, the world was robbed of more and more divine power and started looking worryingly like a ship adrift without its captain. Science at the frontiers threatened certain strongly-held assumptions about the universe. The puzzle of non-Euclidian geometry was even enough of a contemporary issue to appear in Dostoevsky’s Brothers Karamazov when Ivan discusses the ineffability of God:
But you must note this: if God exists and if He really did create the world, then, as we all know, He created it according to the geometry of Euclid and the human mind with the conception of only three dimensions in space. Yet there have been and still are geometricians and philosophers, and even some of the most distinguished, who doubt whether the whole universe, or to speak more widely, the whole of being, was only created in Euclid’s geometry; they even dare to dream that two parallel lines, which according to Euclid can never meet on earth, may meet somewhere in infinity… I have a Euclidian earthly mind, and how could I solve problems that are not of this world?
— Dostoevsky, Brothers Karamzov (1880), Part II, Book V, Chapter 3.
Well Ivan, to quote Hinton, “it is indeed strange, the manner in which we must begin to think about the higher world”. Hinton's solution was a series of coloured cubes that, when mentally assembled in sequence, could be used to visualise a hypercube in the fourth dimension of hyperspace. He provides illustrations and gives instructions on how to make these cubes and uses the word “tesseract” to describe the four-dimensional object.
The term “tesseract”, still used today, might be Hinton’s most obvious legacy, but the genesis of the word is slightly cloudy. He first used it in an 1888 book called A New Era of Thought and initially used the spelling tessaract. In Greek, “τεσσάρα”, meaning “four”, transliterates to “tessara” more accurately than “tessera”, and -act likely comes from “ακτίνες” meaning "rays"; so Hinton’s use suggests the four rays from each vertex exhibited in a hypercube and neatly encodes the idea “four” into his four-dimensional polytope. However, in Latin, “tessera” can also mean “cube”, which is a plausible starting point for the new word. As is sometimes the case, there seems to be some confusion over the Greek or Latin etymology, and we’ve ended up with a bastardization. To confuse matters further, by 1904 Hinton was mostly using “tesseract” — I say mostly because the copies of his books I’ve seen aren’t entirely consistent with the spelling, in all likelihood due to a mere oversight in the proof-reading. Regardless, the later spelling won acceptance while the early version died with its first appearance.
Hinton also promises that when the visualisation is achieved, his cubes can unlock hidden potential. “When the faculty is acquired — or rather when it is brought into consciousness for it exists in everyone in imperfect form — a new horizon opens. The mind acquires a development of power”. It is clear from Hinton’s writing that he saw the fourth dimension as both physically and psychically real, and that it could explain such phenomena as ghosts, ESP, and synchronicities. In an indication of the spatial and mystical significance he afforded it, Hinton suggested that the soul was “a four-dimensional organism, which expresses its higher physical being in the symmetry of the body, and gives the aims and motives of human existence”. Letters submitted to mathematical journals of the time indicate more than one person achieved a disastrous success and found the process of visualising the fourth dimension profoundly disturbing or dangerously addictive. It was rumoured that some particularly ardent adherents of the cubes had even gone mad.
He had said that the geometry of the dream-place he saw was abnormal, non-Euclidian, and loathsomely redolent of spheres and dimensions apart from ours.
— H. P. Lovecraft, The Call of Cthulhu (1928)
Hinton’s ideas gradually pervaded the cultural milieu over the next thirty years or so — prominently filtering down to the Cubists and Duchamp. The arts were affected by two distinct interpretations of higher dimensionality: on the one hand, the idea as a spatial, geometric concept is readily apparent in early Cubism’s attempts to visualise all sides of an object at once, while on the other hand, it becomes a kind of all-encompassing mystical codeword used to justify avant-garde experimentation. “This painting doesn’t make sense? Ah, well, it does in the fourth dimension…” It becomes part of a language for artists exploring new ideas and new spaces. Guillaume Apollinaire was amongst the first to write about the fourth dimension in the arts with his essay Les peintres cubistes in 1913, which veers from one interpretation to another over the course of two paragraphs and stands as one of the best early statements on the phenomenon:
Until now, the three dimensions of Euclid’s geometry were sufficient to the restiveness felt by great artists yearning for the infinite. The new painters do not propose, any more than did their predecessors, to be geometers. But it may be said that geometry is to the plastic arts what grammar is to the art of the writer. Today, scientists no longer limit themselves to the three dimensions of Euclid. The painters have been led quite naturally, one might say by intuition, to preoccupy themselves with the new possibilities of spatial measurement which, in the language of the modern studios, are designated by the term: the fourth dimension. […] Wishing to attain the proportions of the ideal, to be no longer limited to the human, the young painters offer us works which are more cerebral than sensual. They discard more and more the old art of optical illusion and local proportion, in order to express the grandeur of metaphysical forms. This is why contemporary art, even if it does not directly stem from specific religious beliefs, none the less possesses some of the characteristics of great, that is to say religious art.
Whilst most suited to the visual arts, the fourth dimension also made inroads into literature, with Apollinaire and his calligrammes arguably a manifestation. Gertrude Stein with her strikingly visual, mentally disorienting poetry was also accused of writing under its influence, something she refuted in an interview with the Atlantic Monthly in 1935: “Somebody has said that I myself am striving for a fourth dimension in literature. I am striving for nothing of the sort and I am not striving at all but only gradually growing and becoming steadily more aware of the way things can be felt and known in words.” If nothing else, the refutation at least indicates the idea’s long-lasting presence in artistic circles.

Some critics have since tried to back-date higher dimensions in literature to Lewis Carroll and Through the Looking-Glass, although he was, by all accounts, a fairly conservative mathematician who once wrote an article critical of current academic interest in the subject entitled "Euclid and his Modern Rivals" (1873). As a side note, Hinton once invented a game of three-dimensional chess and opined that none of his students could understand it, so perhaps Carroll would have appreciated that.
If anything, the connection between Carroll and hyperspace was the other way round, and the symbolic language employed by Carroll — mirrors, changing proportions, nonsense, topsy-turvy inversions and so on — was picked up by later artists and writers to help prop up their own conceptions of the fourth dimension, which, as we can see, were starting to become a bit of a free for all. Marcel Duchamp, for instance, coined the rather wonderful phrase “Mirrorical return” in a note about the fourth dimension and the Large Glass.
{kind=link}

In the same period that Hinton’s ideas of the fourth dimension were gaining currency among the intellectuals of Europe our “secret sense, our sixth sense” was identified by neurophysiologist Charles Sherrington in 1906. Proprioception, as he called it, is our ability to locate where a body part is when our eyes are closed — in other words, our ability to perceive ourselves in space. And yet the sixth sense means something completely different to us nowadays, associated with another fin-de-siècle obsession: mediumship, the ability to perceive things in the same space but in different dimensions. It is worth noting that in those days, scientists – real, respected, working scientists — apparently looked towards spiritualist mediums for experimental evidence. At the same time, Hinton’s cubes were used in séances as a method of glimpsing the fourth dimension (and hopefully a departed soul or two). Hinton himself published one of his very first articles on the fourth dimension with the sensational subtitle “Ghosts Explained”. In defence of the era’s more eccentric ideas, though, so much was explained or invented in so very few years, that it must have seemed only a matter of time before life’s greatest mysteries were finally solved. In any case, the craze over a mystical fourth dimension began to fade while the sensible sixth sense of proprioception just never really caught on.

But are not the dreams of poets and the tales of travellers notoriously false?
– H.P. Lovecraft, “The Street” (1919)
By the late 1920s, Einsteinian Space-Time had more or less replaced the spatial fourth dimension in the minds of the public. It was a cold yet elegant concept that ruthlessly killed off the more romantic idea of strange dimensions and impossible directions. What had once been the playground of spiritualists and artists was all too convincingly explained. As hard science continued to rise in the early decades of the twentieth century, the fin-de-siècle’s more outré ideas continued to decline. Only the Surrealists continued to make reference to it, as an act of rebellion and vindication of the absurd. The idea of a real higher dimension linking us together as One sounded all a bit too dreamy, a bit too old-fashioned for a new century that was picking up speed, especially when such vague and multifarious explanations were trumped by the special theory of relativity. Hinton was as much hyperspace philosopher as scientist and hoped humanity would create a more peaceful and selfless society if only we recognised the unifying implications of the fourth dimension. Instead, the idea was banished to the realms of New Age con-artists, reappearing these days updated and repackaged as the fifth dimension. Its shadow side, however, proved hopelessly alluring to fantasy writers who have seen beyond the veil, and bring back visions of horror from an eldritch land outside of time and space that will haunt our nightmares with its terrible geometry, where tentacles and abominations truly horrible sleep beneath the Pacific Ocean waiting to bring darkness to our world… But still we muddle on through.
What do we know… of the world and the universe about us? Our means of receiving impressions are absurdly few, and our notions of surrounding objects infinitely narrow. We see things only as we are constructed to see them and can gain no idea of their absolute nature. With five feeble senses we pretend to comprehend the boundlessly complex cosmos.
— H.P. Lovecraft, From Beyond (1920)
This essay was originally published by The Public Domain Review under a Creative Commons Attribution-ShareAlike 3.0 license.